:quality(50))
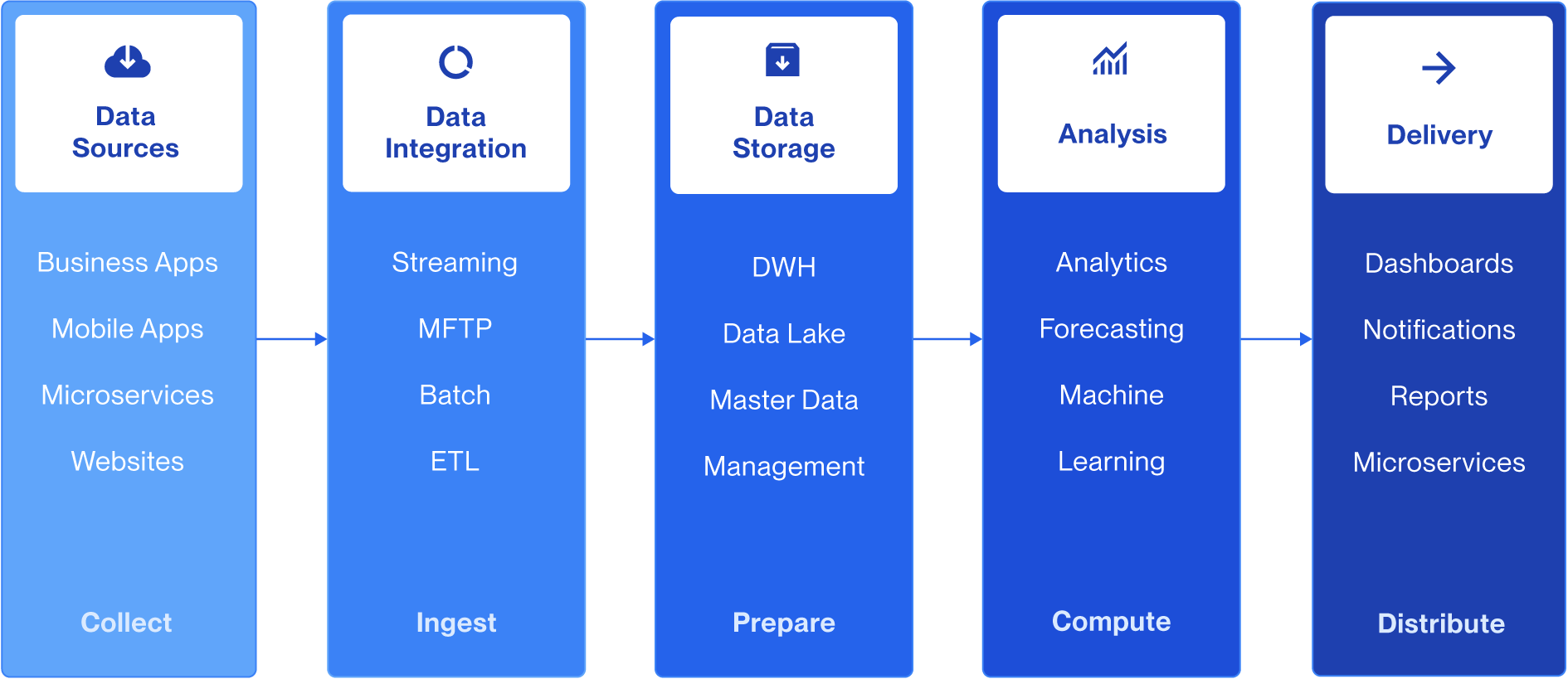
Was ist Data Pipeline Orchestration?
Data Pipeline Orchestration ist die automatisierte Steuerung von Daten-Workflows. Dazu gehören die Definition der Abfolge einzelner Aufgaben wie Extraktion, Transformation, Laden, Validierung und Bereitstellung, die Durchsetzung von Abhängigkeiten zwischen diesen Schritten, das Handling von Fehlern sowie die Überwachung der Ausführung über alle angebundenen Systeme hinweg.
Man kann sie sich wie einen Dirigenten für die Dateninfrastruktur vorstellen. Die Orchestrierung spielt die Instrumente nicht selbst, sorgt aber dafür, dass jeder Bestandteil zum richtigen Zeitpunkt, in der richtigen Reihenfolge und mit den richtigen Eingaben zusammenspielt.
Kurzdefinition
Eine Datenpipeline transportiert Daten von der Quelle zum Zielsystem. Die Orchestrierung ist die Ebene, die festlegt, wann, in welcher Reihenfolge und unter welchen Bedingungen jeder einzelne Schritt innerhalb dieser Pipeline ausgeführt wird.
Im Gegensatz zu einfachen Schedulern, die Jobs zu festen Zeiten starten, arbeiten Orchestrierungssysteme abhängigkeitsbasiert und ereignisgesteuert. Eine nachgelagerte Aufgabe wird beispielsweise erst dann ausgeführt, wenn vorgelagerte Prozesse erfolgreich abgeschlossen wurden und nicht lediglich, weil eine festgelegte Uhrzeit erreicht wurde.
Warum Data Pipeline Orchestration wichtig ist
Moderne Unternehmen betreiben Dutzende oder sogar Hunderte voneinander abhängiger Pipelines über Cloud-Plattformen, On-Premises-Rechenzentren, SaaS-Anwendungen und Mainframe-Systeme hinweg. Ohne Orchestrierung wird diese Komplexität sehr schnell unbeherrschbar.
Eliminiert manuelles Abhängigkeitsmanagement
Wenn Pipeline A Pipeline B versorgt und diese wiederum Pipeline C speist, kann ein Fehler in Schritt A unbemerkt die gesamte Kette beeinträchtigen.
Orchestrierung setzt Abhängigkeitsregeln automatisch durch: nachgelagerte Jobs warten, Retry-Mechanismen greifen automatisch und Alerts werden ohne manuelles Eingreifen ausgelöst.
Erfahren Sie mehr darüber, wie Workload Automation diese manuellen Abhängigkeiten eliminiert.
Sorgt für End-to-End-Transparenz
Ohne zentrale Orchestrierung bleiben Fehler oft unsichtbar, bis nachgelagerte Prozesse beeinträchtigt werden.
Enterprise-Orchestrierungsplattformen bieten eine zentrale Übersicht über sämtliche Pipeline-Aktivitäten, darunter Logs, SLA-Status, Ausführungshistorien und Anomalie-Warnungen. So können Datenteams eingreifen, bevor Fachbereiche betroffen sind.
Genau hier wird Observability für Workload Automation geschäftskritisch.
Gewährleistet Datenqualität und SLA-Compliance
Orchestrierte Pipelines können Datenqualitätsprüfungen direkt als Abhängigkeiten integrieren. Schlägt ein Validierungsschritt fehl, werden nachgelagerte Ladeprozesse automatisch blockiert.
Dadurch bleiben analytische Ergebnisse zuverlässig und vereinbarte Daten-SLAs werden konsistent eingehalten.
Laut dem Gartner Magic Quadrant erwarten Unternehmenskunden ausdrücklich, dass SOAP-Plattformen „geschäftskritische Zuverlässigkeit“ sowie „zentrale Kontrolle“ über ihre gesamte hybride IT-Landschaft hinweg gewährleisten.
Skaliert mit wachsender Business-Komplexität
Eine manuell gestartete Pipeline, die mit 10 Jobs funktioniert, bricht bei 1.000 Jobs unweigerlich zusammen.
Orchestrierungsplattformen skalieren horizontal und verarbeiten Tausende paralleler Jobs über Multi-Cloud- und hybride Umgebungen hinweg, ohne dass eine grundlegende Neuarchitektur erforderlich wird.
Ereignisgesteuerte Automatisierung ist dabei ein zentraler Treiber für diese Skalierbarkeit.
Beschleunigt KI- und Analytics-Workflows
KI- und ML-Pipelines erfordern eine klar definierte Reihenfolge einzelner Prozessschritte:
Daten müssen vor dem Feature Engineering bereinigt werden
Features müssen vor dem Modelltraining validiert werden
Modelle müssen vor dem Deployment bewertet werden
Orchestrierung setzt diese Abläufe in großem Maßstab zuverlässig durch und macht automatisierte Daten-Workflows zu einer grundlegenden Voraussetzung moderner KI-Operations.
Data Pipeline Orchestration vs. Job Scheduling
Diese Begriffe werden häufig verwechselt, beschreiben jedoch grundlegend unterschiedliche Anforderungen.
Hier sind die wichtigsten Unterschiede.
| Faktor | Job Scheduling | Data Pipeline Orchestration |
|---|---|---|
| Primärer Trigger | Zeitbasiert (Cron, Kalender) | Ereignisgesteuert + zeitbasiert + abhängigkeitsbasiert |
| Umgang mit Abhängigkeiten | Keine oder eingeschränkte Unterstützung | Vollständiges Management von Upstream- und Downstream-Abhängigkeiten |
| Fehlerbehandlung | Einfache Retries oder Alerts | Bedingte Verzweigungen, Rollback- und Eskalationslogik |
| Systemübergreifende Reichweite | Meist auf eine Plattform beschränkt | Multi-Cloud-, Hybrid-, On-Premises- und SaaS-Umgebungen |
| Observability | Nur Job-Logs | End-to-End-Lineage von Pipelines sowie SLA-Dashboards |
| Dynamische Ausführung | Statische Jobdefinitionen | Dynamische Workflow-Generierung auf Basis von Runtime-Kontext |
| Geeignete Einsatzbereiche | Routinemäßige, zeitgesteuerte Batch-Jobs | Komplexe, voneinander abhängige Daten-Workflows über mehrere Systeme hinweg |
Profi-Tipp
Wenn Ihre Pipeline aus mehr als drei voneinander abhängigen Schritten besteht oder mehrere Systemgrenzen überschreitet, benötigen Sie Orchestrierung.
Gängige Architekturmodelle für Datenpipelines
Datenpipelines sind keine Einheitslösung. Die passende Architektur hängt von Ihren Latenzanforderungen, Ihrer Systemlandschaft und den zu verarbeitenden Datenmengen ab.
Im Folgenden finden Sie die vier wichtigsten Architekturmodelle für Enterprise-Umgebungen.
Batch-ETL-Pipelines
Das etablierteste Modell basiert darauf, dass Daten in festgelegten Intervallen, beispielsweise stündlich, täglich oder wöchentlich, aus Quellsystemen extrahiert, gemäß definierter Geschäftsregeln transformiert und anschließend in ein Data Warehouse oder einen Data Lake geladen werden.
Rolle der Orchestrierung
Erzwingt die korrekte Reihenfolge von Extraktion → Transformation → Validierung → Laden
Steuert Retry-Mechanismen bei temporären Fehlern
Startet nachgelagerte Analytics-Jobs erst nach erfolgreicher Bestätigung des Ladevorgangs
Typische Einsatzbereiche: Finanzreporting, regulatorische Datenmeldungen sowie End-of-Day-Abstimmungen in Banken- und Versicherungsumgebungen.
Erfahren Sie mehr darüber, wie Workload Automation diese Workflows unterstützt.
Streaming- und ereignisgesteuerte Pipelines
Anstatt Daten in festen Intervallen gesammelt zu verarbeiten, verarbeiten Streaming-Pipelines Daten kontinuierlich in Echtzeit, sobald Ereignisse aus Message Queues wie Kafka oder Kinesis, IoT-Sensoren, Event Streams von Anwendungen oder API-Webhooks eintreffen.
Rolle der Orchestrierung
Steuert ereignisbasierte Ausführungen und verarbeitet Backpressure-Situationen
Koordiniert zustandsbehaftete Verarbeitungsschritte
Gewährleistet Exactly-Once-Delivery-Semantik über verschiedene Systeme hinweg
Typische Einsatzbereiche: Echtzeit-Betrugserkennung, Event-Monitoring in Lieferketten sowie Netzwerkbetrieb in der Telekommunikation.
Hybride Pipelines (Batch + Streaming)
Viele Enterprise-Anwendungsfälle benötigen beides: Streaming-Ingestion für die latenzarme Verarbeitung von Events sowie Batch-Verarbeitung für historische Abstimmungen und Analysen. Dieses Lambda-Architecture-Modell oder dessen moderne Kappa-Variante erfordert eine Orchestrierung, die beide Ausführungsmodelle gleichzeitig verwalten kann.
Rolle der Orchestrierung
Koordiniert Übergaben zwischen Streaming- und Batch-Layern
Stellt sicher, dass Batch-Reconciliation-Jobs die korrekten Streaming-Checkpoints verwenden
Verwaltet SLAs über beide Verarbeitungsmodelle hinweg
Typische Einsatzbereiche: Warenbestandssysteme im Einzelhandel, Qualitätskontrolle in der Fertigung sowie Plattformen für Finanzrisikomanagement.
Multi-System-Pipelines (Cloud + On-Premises)
Enterprise-Daten befinden sich selten an nur einem Ort. Eine einzelne Pipeline kann Daten aus einem lokalen SAP-System extrahieren, sie über Databricks in der Cloud transformieren, gegen Snowflake validieren und anschließend in ein Azure Data Warehouse laden, alles innerhalb eines einzigen orchestrierten Workflows.
Rolle der Orchestrierung
Abstrahiert Infrastrukturgrenzen
Verwaltet Credentials und Konnektivität über verschiedene Umgebungen hinweg
Gewährleistet konsistente Ausführungslogiken unabhängig davon, wo einzelne Tasks ausgeführt werden
Typische Einsatzbereiche: SAP-Modernisierungsprojekte, Cloud-Migrationsphasen sowie hybride BFSI-Umgebungen, in denen Mainframes parallel zu Cloud-nativen Analytics-Plattformen betrieben werden.
Profi-Tipp
Die Zukunft der Workload Automation wird zunehmend durch diese Fähigkeit zur systemübergreifenden und Cross-Cloud-Orchestrierung geprägt. Für Unternehmen mit komplexen hybriden IT-Landschaften ist das keine Option mehr, sondern eine Notwendigkeit.
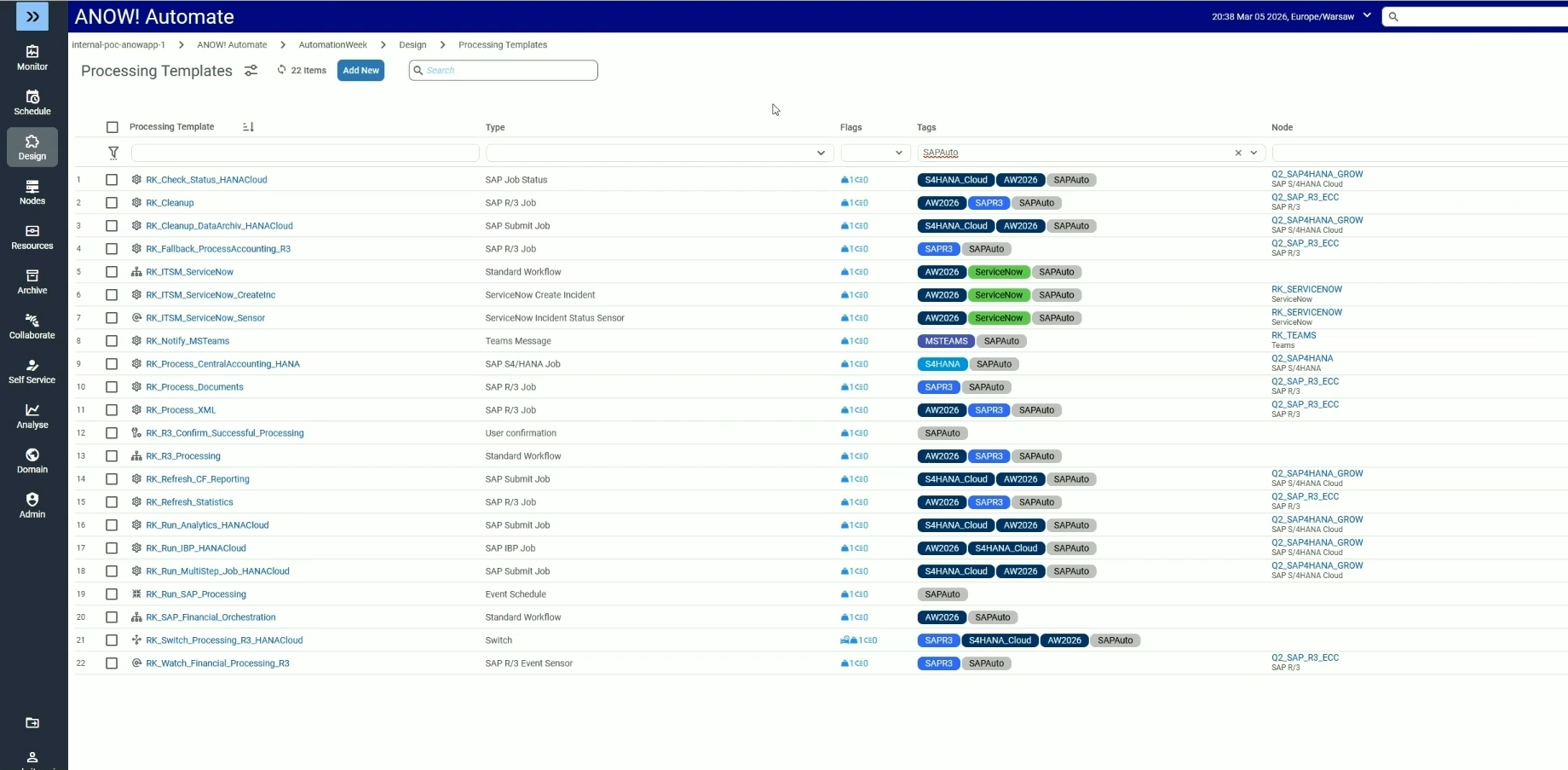
Kernkomponenten der Data Pipeline Orchestration
Um zu verstehen, was eine Orchestrierungsplattform tatsächlich leistet, muss man ihre zentralen Bausteine kennen.
Scheduler- und Trigger-Engine
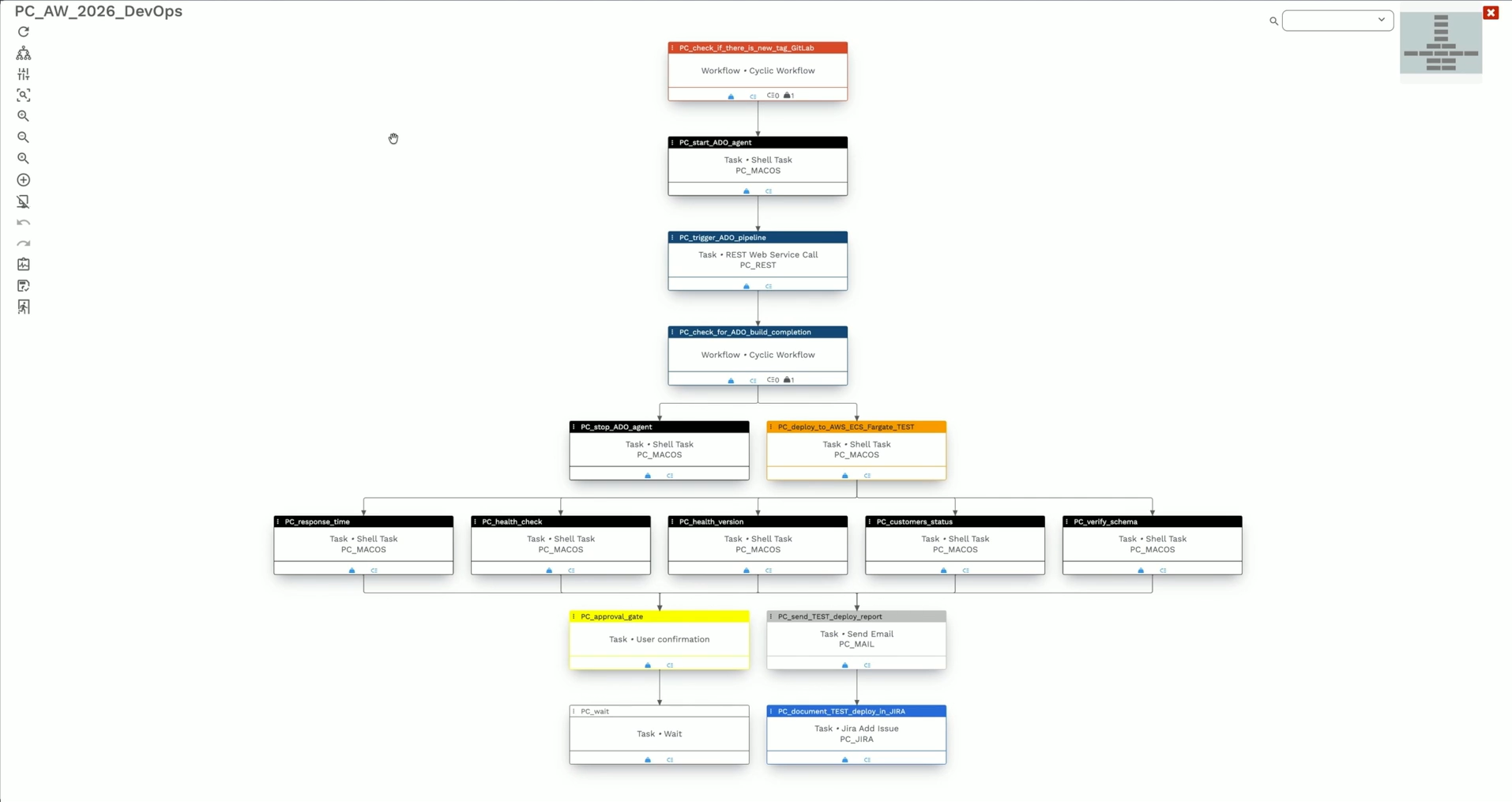
Dies bildet das Ausführungs-Backbone der Plattform und geht weit über klassische Cron-basierte Zeitsteuerung hinaus. Unterstützt werden ereignisgesteuerte, abhängigkeitsbasierte und API-gesteuerte Ausführungen.
Enterprise-Orchestratoren unterstützen sensorbasierte Trigger, beispielsweise wenn eine Datei in einem S3-Bucket eingeht, ein Datenbankeintrag aktualisiert wird oder ein definierter Schwellenwert in einem Monitoring-System überschritten wird. Diese Ereignisse dienen als Bedingungen für die Ausführung von Pipelines.
Workflow-Designer
Moderne Plattformen bieten sowohl visuelle Low-Code-Ansätze per Drag-and-Drop als auch codebasierte Workflow-Definitionen über YAML, JSON oder Python. Enterprise-Grade-Orchestratoren unterstützen zudem Versionskontrolle und Git-Integration für CI/CD-Prozesse, was insbesondere für DevOps-Teams essenziell ist, die Automatisierung als Code verwalten.
Engine für Fehlerbehandlung und Recovery
Diese Komponente verarbeitet Task-Fehler mithilfe konfigurierbarer Retry-Logiken, bedingter Verzweigungen, Rollback-Funktionen und definierter Eskalationspfade.
Ohne robuste Fehlerbehandlung kann bereits ein einzelner temporärer Netzwerkausfall einen vollständigen Ausfall der gesamten Pipeline verursachen.
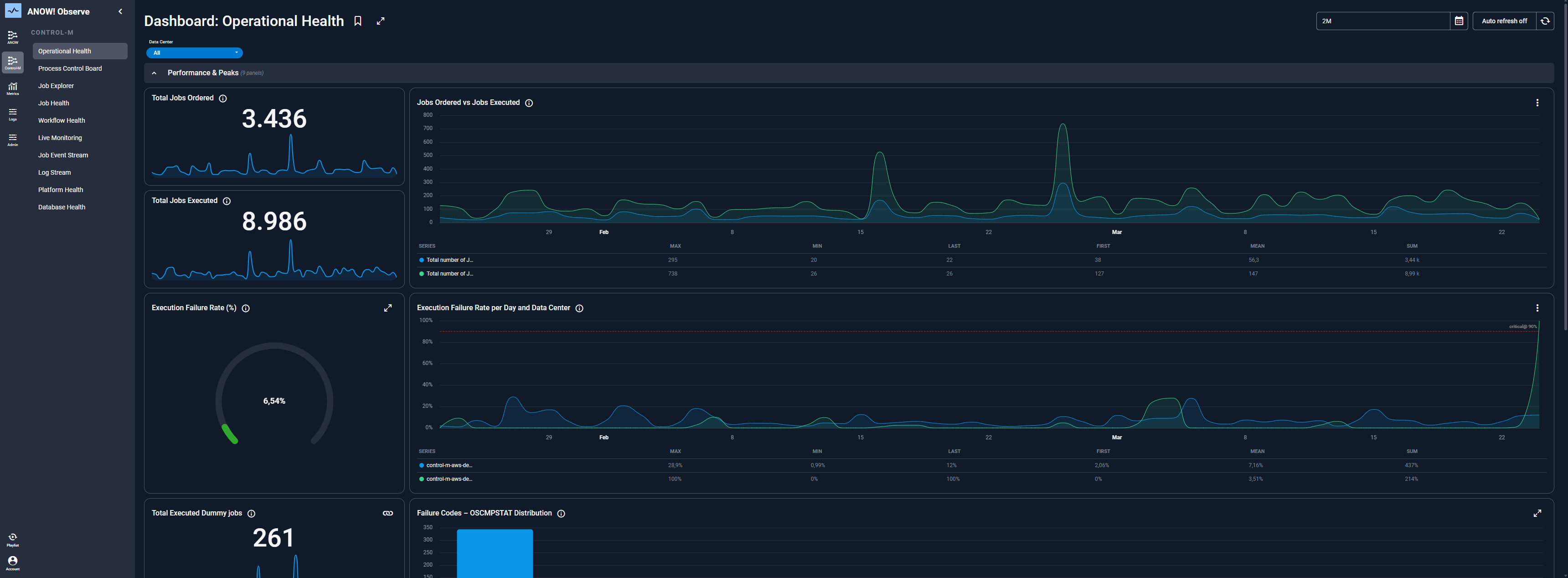
Monitoring-, Logging- und Observability-Layer
Diese Ebene erfasst Ausführungs-Telemetrie und stellt sie über Dashboards, Alerts und Audit-Logs bereit. Fortschrittliche Plattformen integrieren OpenTelemetry-Unterstützung, um standardisierte Observability über die gesamte IT-Operations-Management-Landschaft hinweg zu gewährleisten.
Diese Schicht spielt außerdem eine zentrale Rolle für Log-Management und Compliance-Reporting.
Integrations- und Konnektivitätsebene
Diese Ebene bestimmt die Breite nativer Integrationen und damit, welche Systeme Ihre Orchestrierungsplattform koordinieren kann.
Enterprise-Umgebungen benötigen Konnektivität zu Cloud-Services wie AWS, Azure und GCP, Datenplattformen wie Snowflake, Databricks und BigQuery, ERP-Systemen wie SAP, ITSM-Tools wie ServiceNow sowie zu Legacy-Infrastrukturen und das alles über sichere und auditierbare Verbindungen hinweg.

Herausforderungen und wie man sie bewältigt
Selbst mit der richtigen Plattform bringt Data Pipeline Orchestration typische Herausforderungen mit sich.
Hier erfahren Sie, womit Sie rechnen müssen und wie Sie die jeweiligen Herausforderungen erfolgreich lösen.
#1. Pipeline-Sprawl und fehlende zentrale Transparenz
Mit zunehmender Anzahl an Pipelines verlieren Teams schnell den Überblick darüber, welche Prozesse aktuell laufen, welche voneinander abhängen und welche Fehler unbemerkt bleiben. Einzelne Pipeline-Verantwortliche verwalten ihre eigenen Scheduler, wodurch unsichtbare Abhängigkeiten und konkurrierende Ressourcennutzung entstehen.
Die Lösung: Konsolidieren Sie die gesamte Pipeline-Orchestrierung auf einer zentralen Plattform mit einheitlichen Dashboards und Abhängigkeitsdiagrammen. Eine zentrale Observability-Schicht, insbesondere auf Basis von OpenTelemetry-Standards, verschafft Teams Echtzeit-Transparenz über sämtliche Pipelines hinweg.
#2. Fragiles Abhängigkeitsmanagement im großen Maßstab
Statische Abhängigkeitsdefinitionen brechen schnell zusammen, wenn vorgelagerte Systeme Schemas ändern, Verzögerungen verursachen oder nur teilweise ausfallen. Hart codierte Pipeline-Logik erfordert bei jeder Änderung der Umgebung manuelle Eingriffe.
Die Lösung: Setzen Sie auf dynamische Workflow-Generierung mit sensor- beziehungsweise ereignisgesteuerten Triggern anstelle statischer Zeitpläne. Plattformen wie die ANOW! Suite unterstützen Event-Driven Orchestration und reagieren automatisch auf Zustandsänderungen vorgelagerter Systeme, anstatt an fehlerhaften Zeitplänen zu scheitern.
#3. SLA-Monitoring über hybride Umgebungen hinweg
Wenn Pipelines sowohl On-Premises- als auch Cloud-Systeme umfassen, wird SLA-Tracking schnell fragmentiert. Teams erkennen SLA-Verletzungen häufig erst dann, wenn Fachbereiche fehlende Daten melden, anstatt proaktiv reagieren zu können.
Die Lösung: Implementieren Sie prädiktives SLA-Monitoring, das gefährdete Pipelines erkennt, bevor ein SLA-Verstoß eintritt. Observability für Workload-Automation-Umgebungen liefert die notwendige Telemetrie-Basis für ein proaktives SLA-Management.
#4. Sicherheit und Compliance in Datenpipelines
Datenpipelines verarbeiten häufig sensible Informationen wie personenbezogene Daten, Finanzdaten oder Gesundheitsinformationen. Die Einhaltung rollenbasierter Zugriffsrechte, vollständiger Audit-Trails sowie regulatorischer Anforderungen wie DSGVO oder HIPAA bleibt über den gesamten Pipeline-Lebenszyklus hinweg eine permanente Herausforderung.
Die Lösung: Setzen Sie auf tagbasierte Sicherheitsmechanismen und Row-Level-Security für Pipeline-Komponenten und nicht nur auf modulbasierte Zugriffskontrollen. Dynamische Berechtigungsvergabe, also das temporäre Zuweisen von Zugriff auf ein bestimmtes Pipeline-Objekt während der Ausführung und anschließende Entziehen der Rechte, gewährleistet das Prinzip der minimalen Rechtevergabe selbst in komplexen Orchestrierungsumgebungen.
#5. Migration von Legacy-Schedulern
Viele Unternehmen betreiben ihre Pipelines noch auf AutoSys-, Control-M- oder klassischen Cron-basierten Systemen, die über Jahrzehnte gewachsen sind. Die Migration dieser Workloads auf moderne Orchestrierungsplattformen ohne Beeinträchtigung des Produktivbetriebs ist technisch und organisatorisch äußerst anspruchsvoll.
Die Lösung: Achten Sie auf Plattformen mit Zero-Touch-Migrationsfunktionen und einer Zero-Downtime-Deployment-Architektur. Die Möglichkeit, Legacy- und moderne Pipelines während der Übergangsphase parallel zu betreiben, reduziert das Risiko erheblich. Der Migrationsansatz von Beta Systems wurde speziell für Unternehmen entwickelt, die Legacy-Workload-Automation-Anbieter ablösen möchten.
Best Practices für zuverlässige Data Pipeline Orchestration
So implementieren Sie Data Pipeline Orchestration erfolgreich in Ihrem Unternehmen.
#1. Modellieren Sie sämtliche Abhängigkeiten explizit
Gehen Sie niemals davon aus, dass vorgelagerte Daten bereits verfügbar sind. Stattdessen sollten Abhängigkeiten direkt in der Orchestrierungsschicht definiert werden.
Jede Pipeline sollte ihre Inputs, Outputs und Upstream-Abhängigkeiten deklarieren, damit der Orchestrator die Ausführungsreihenfolge durchsetzen und Fehler direkt an der Ursache sichtbar machen kann und nicht erst in nachgelagerten Prozessen.
#2. Implementieren Sie idempotente Pipeline-Logik
Entwerfen Sie Pipeline-Tasks so, dass sie nach Teilfehlern sicher erneut ausgeführt werden können, ohne Daten zu duplizieren oder Zustände zu beschädigen. Dadurch kann Retry-Logik, eine zentrale Funktion moderner Orchestrierung, aggressiv eingesetzt werden, was Ausfallzeiten durch temporäre Fehler drastisch reduziert.
Dies ist außerdem ein Grundprinzip zuverlässiger Workflow-Orchestrierung.
#3. Behandeln Sie Observability als zentrale Anforderung
Betrachten Sie Pipeline-Telemetrie als geschäftskritische Produktionsinfrastruktur und nicht als nachträgliche Ergänzung. Erstellen Sie Dashboards für SLA-Tracking, Anomalie-Erkennung und historische Trendanalysen, bevor Sie sie dringend benötigen.
Die ANOW! Observe-Komponente wurde speziell für diesen Einsatzzweck in Workload-Automation-Umgebungen entwickelt.
#4. Nutzen Sie Enterprise-Grade-Orchestrierungsplattformen statt isolierter Einzellösungen
Point Solutions wie Single-Cloud-Scheduler oder spezialisierte ETL-Scheduler lösen nur einzelne Teilprobleme und schaffen neue Silos.
Wie Gartner im Magic Quadrant vom August 2025 hervorhob, erwarten Enterprise-Kunden eine einheitliche Plattform, die zentrale Kontrolle bietet und Prozesse End-to-End über die gesamte hybride IT-Landschaft hinweg orchestriert.
Plattformen wie ANOW! Automate bieten mehr als 600 native Out-of-the-Box-Integrationen, mehr als jeder andere WLA-Anbieter, kombiniert mit Cloud-Native-Deployment, OpenTelemetry-nativer Observability und einer Zero-Downtime-Upgrade-Architektur.
#5. Nutzen Sie Versionskontrolle und CI/CD-Praktiken für Pipeline-Definitionen
Behandeln Sie Workflow-Definitionen wie Code. Speichern Sie diese in Git, prüfen Sie Änderungen über Pull Requests und deployen Sie sie über CI/CD-Pipelines.
Dadurch verhindern Sie unkontrollierte Änderungen an produktiven Pipelines und ermöglichen schnelle Rollbacks im Fehlerfall. Jobs-as-Code-Funktionen gelten heute als Standardanforderung moderner Enterprise-Orchestrierung.
Automatisieren Sie komplexe Daten-Workflows mit Beta Systems
Data Pipeline Orchestration ist für Unternehmen mit komplexen hybriden Datenlandschaften längst keine Option mehr. Sie bildet heute die Grundlage für zuverlässige Analytics, AI Operations und geschäftskritische Automatisierung.
Beta Systems wurde im Gartner Magic Quadrant 2025 für Service Orchestration and Automation Platforms als Leader ausgezeichnet und ist bekannt für seine einheitliche Observability, umfassende Integrationsmöglichkeiten und hohe Kundenbindung in geschäftskritischen Branchen.
Möchten Sie Ihren Legacy-Scheduler ablösen oder fragmentierte Pipeline-Tools konsolidieren?
Entdecken Sie jetzt die ANOW! Suite.
:quality(50))
:quality(50))
:quality(50))