:quality(50))
Was ist Data Workflow Automation?
Bei der Automatisierung von Daten-Workflows werden Datenprozesse mithilfe von Software Ende zu Ende orchestriert, sodass sie automatisch, zuverlässig und skalierbar ablaufen.
Anstatt Skripte manuell auszuführen oder Cron-Jobs miteinander zu verknüpfen, definieren Sie Trigger, Aufgaben, Abhängigkeiten und Benachrichtigungen. Die Plattform übernimmt den Rest.
Ein typischer automatisierter Daten-Workflow sieht so aus:
Trigger: Eine neue Datei landet im Cloud Storage oder ein API-Call wird ausgelöst.
Datenaufnahme: Daten werden automatisch aus dem Quellsystem geladen.
Validierung und Bereinigung: Schema-Checks, Nullwert-Filter und Duplikaterkennung laufen ohne manuelles Eingreifen.
Transformation: SQL-Transformationen, Anreicherung oder ML-Pipelines werden in der richtigen Reihenfolge ausgeführt.
Bereitstellung und Benachrichtigung: Die verarbeiteten Daten landen im Data Warehouse oder BI-Tool, inklusive Alerts bei Erfolg oder Fehler.
→ Weiterlesen: Was ist Workload-Automatisierung?
Warum die Automatisierung von Daten-Workflows wichtig ist
Unternehmen automatisieren Daten-Workflows nicht nur aus Bequemlichkeit. Der geschäftliche Nutzen ist messbar und die Auswirkungen im Betrieb sind unmittelbar spürbar.
Automatisierung ist längst auf C-Level angekommen: 90 Prozent der Führungskräfte halten sie für entscheidend oder sehr wichtig zur Erreichung ihrer Unternehmensziele. Gleichzeitig treiben 86 Prozent entsprechende Initiativen aktiv voran.
Hier die wichtigsten Gründe im Überblick.
Weniger Fehler, höhere Datenqualität
Manuelle Dateneingaben und individuell geschriebene Skripte führen zwangsläufig zu Fehlern, die sich entlang der gesamten Pipeline fortpflanzen. Das verfälscht Reports, verzerrt Analysen und kann Machine-Learning-Modelle beeinträchtigen.
Automatisierung stellt sicher, dass Validierungsregeln in jedem Schritt konsistent angewendet werden und reduziert manuelle Fehler deutlich.
Durch integrierte Data-Quality-Checks und Anomalieerkennung werden Probleme früh erkannt, bevor sie überhaupt im Data Warehouse ankommen.
Mehr Effizienz und Zeitgewinn
Durch die Automatisierung wiederkehrender Aufgaben gewinnen Teams spürbar Zeit zurück. Für Data-Engineering-Teams, die zahlreiche Pipelines über verschiedene Cloud-Umgebungen hinweg betreiben, summiert sich dieser Effekt schnell.
Branchenstatistik
Laut Gartner Magic Quadrant 2024 für Service-Orchestrierung und Automatisierungsplattformen wächst der Markt deutlich, da Unternehmen von isolierten Scheduler-Lösungen auf zentrale Orchestrierungsplattformen umsteigen. Workload-Automatisierung und Observability gehören dabei inzwischen untrennbar zusammen.
Compliance und Audit-Fähigkeit
Automatisiertes Workflow-Management hilft Unternehmen, regulatorische Anforderungen deutlich besser zu erfüllen.
In regulierten Branchen wie Banken, Versicherungen oder Pharma sind automatisierte Logs, SLA-Dashboards und Audit-Trails unverzichtbar.
Gerade in Europa setzen Unternehmen im Kontext von DORA und vergleichbaren Vorgaben zunehmend auf Workload-Automatisierungsplattformen, um Compliance im großen Maßstab sicherzustellen und nachvollziehbar zu dokumentieren, insbesondere im IT-Betrieb.
Arten der Automatisierung von Daten-Workflows
Die Automatisierung von Daten-Workflows lässt sich nicht in eine einzelne Kategorie einordnen. Sie umfasst mehrere Ebenen des modernen Data Stack.
Ein Verständnis der verschiedenen Arten hilft Unternehmen dabei, für jede Ebene die passenden Tools auszuwählen.
Automatisierung von Datenpipelines
Das ist die häufigste Form: die Automatisierung der Bewegung und Transformation von Daten zwischen Systemen. Dazu gehören unter anderem:
ETL-Prozesse (Extract, Transform, Load)
Datenaufnahme aus APIs und Datenbanken
Bereitstellung in Cloud Storage oder Data Warehouses
Tools wie Azure Data Factory oder AWS Glue arbeiten auf dieser Ebene. Übergreifende Orchestrierungsplattformen im Enterprise-Umfeld übernehmen dagegen die Steuerung von Zeitplänen, Abhängigkeiten und SLA-Monitoring über alle Pipelines hinweg.
Ereignisgesteuerte und Cloud-basierte Workflow-Automatisierung
Wussten Sie, dass rund 30 Prozent aller Workload-Automatisierungs-Jobs inzwischen in der Public Cloud laufen und weitere 14 Prozent in hybriden Umgebungen?
Im Gegensatz zu festen Zeitplänen werden bei der ereignisgesteuerten Automatisierung Workflows durch konkrete Ereignisse ausgelöst. Das kann zum Beispiel ein Datei-Upload, eine API-Antwort, ein überschrittener Schwellenwert oder eine Nachricht in einer Queue sein.
Cloud-basierte Workflow-Automatisierung erweitert dieses Prinzip auf verschiedene Cloud-Umgebungen wie Google Cloud, AWS oder Azure. Dabei werden Services wie Cloud Run, Cloud Scheduler oder Secret Manager zu konsistenten, nachvollziehbaren Datenflüssen orchestriert.

→ Weiterlesen: Wie ereignisgesteuerte Automatisierung die Effizienz steigert
KI- und Machine-Learning-Pipeline-Automatisierung
Mit der zunehmenden Verbreitung von KI wächst auch der Bedarf, die zugrunde liegenden Workflows zu automatisieren.
Machine-Learning-Pipelines umfassen typischerweise Schritte wie Datenaufnahme, Feature Engineering, Modelltraining und Inferenz. Sie benötigen dieselben Mechanismen wie klassische Datenprozesse, etwa für Abhängigkeitsmanagement, SLA-Überwachung und Observability.
KI-gestützte Workflow-Automatisierung geht noch einen Schritt weiter: Sie ermöglicht intelligente Anomalieerkennung, adaptive Zeitplanung und automatisierte Fehlerbehebung, wodurch manuelle Eingriffe deutlich reduziert werden.
Pro-Tipp
Wenn Sie Automatisierungstools für KI- und ML-Workloads evaluieren, achten Sie auf native Integrationen mit Plattformen wie AWS SageMaker, Databricks oder BigQuery. Beschränken Sie sich nicht nur auf generische API-Anbindungen. Native Konnektoren sorgen für konsistente Metadaten, saubere Fehlerweitergabe und transparente SLA-Überwachung entlang der gesamten Machine-Learning-Pipeline.
Automatisierung von Analyse- und Transformations-Workflows
Diese Ebene konzentriert sich auf die Automatisierung von Datenaufbereitung und Analyse. Ziel ist es, rohe, eingehende Daten in strukturierte und analysefertige Modelle zu überführen.
Tools wie dbt sind hier angesiedelt. Sie versionieren SQL-Transformationen und stellen durch automatisierte Tests die Datenqualität sicher.
Diese Ebene ist von der Pipeline-Orchestrierung zu unterscheiden, auch wenn beide in einer modernen Datenarchitektur eng zusammenarbeiten.
→ Verwandtes Thema: Kubernetes Scheduling für Workload-Automatisierung
Zentrale Komponenten von Data Workflow Automation
Ein leistungsfähiges System zur Automatisierung von Daten-Workflows besteht aus mehreren miteinander verzahnten Komponenten. Jede dieser Ebenen erfüllt eine eigene Aufgabe, damit Daten zuverlässig von der Quelle bis zum Zielsystem gelangen.
Orchestrierungs-Engine
Das Herzstück jeder Automatisierungsplattform: Die Orchestrierungs-Engine steuert Abhängigkeiten zwischen Workflows, plant Ausführungen, kümmert sich um Wiederholungen bei Fehlern und stellt sicher, dass Jobs in der richtigen Reihenfolge über verteilte Systeme hinweg laufen.
Native Integrationen und Konnektoren
Der Nutzen einer Automatisierungsplattform hängt maßgeblich davon ab, wie gut sie sich in bestehende Datenlandschaften integrieren lässt.
Native Konnektoren für Snowflake, BigQuery, SQL Server, Azure Data Factory, dbt, Apache Airflow und viele weitere Systeme ersetzen fehleranfällige, individuell entwickelte Skripte.
Beta Systems bietet beispielsweise über 600 sofort verfügbare Integrationen für Cloud-, DevOps-, ERP-, ITSM- und Daten-Tools.
Observability- und Monitoring-Layer
Automatisierte Workflows, die im Hintergrund „unsichtbar“ laufen, sind ein Risiko, kein Vorteil.
Ein integrierter Observability-Layer sorgt für Echtzeit-Transparenz über den Zustand von Pipelines, die Einhaltung von SLAs, den Status einzelner Jobs sowie über Fehler und Störungen.
Moderne Plattformen setzen auf OpenTelemetry-native Observability und erzeugen Metriken, Logs und Traces, die als Grundlage für KI-gestützte Anomalieerkennung und automatisierte Fehlerbehebung dienen.
→ Weiterlesen: Was Observability in modernen IT-Operations bedeutet
Datenqualität und Validierung
Automatisierte Prüfregeln wie Schema-Checks, Nullwert-Erkennung, Duplikatfilterung, Adressvalidierung oder allgemeine Datenbereinigung greifen bereits bei der Datenaufnahme und während der Transformation.
Damit wird Datenqualität von einer manuellen Kontrollaufgabe zu einem kontinuierlichen, automatisierten Bestandteil jeder Pipeline.
Wichtige Tools für die Automatisierung von Daten-Workflows
Der Markt für Daten-Workflow-Automatisierung umfasst Orchestrierungsplattformen, Transformationstools und cloud-native Scheduler.
Hier ist ein realistischer Vergleich der drei relevantesten Plattformen für Enterprise-Datenteams im Jahr 2026.
Beta Systems ANOW! Automate
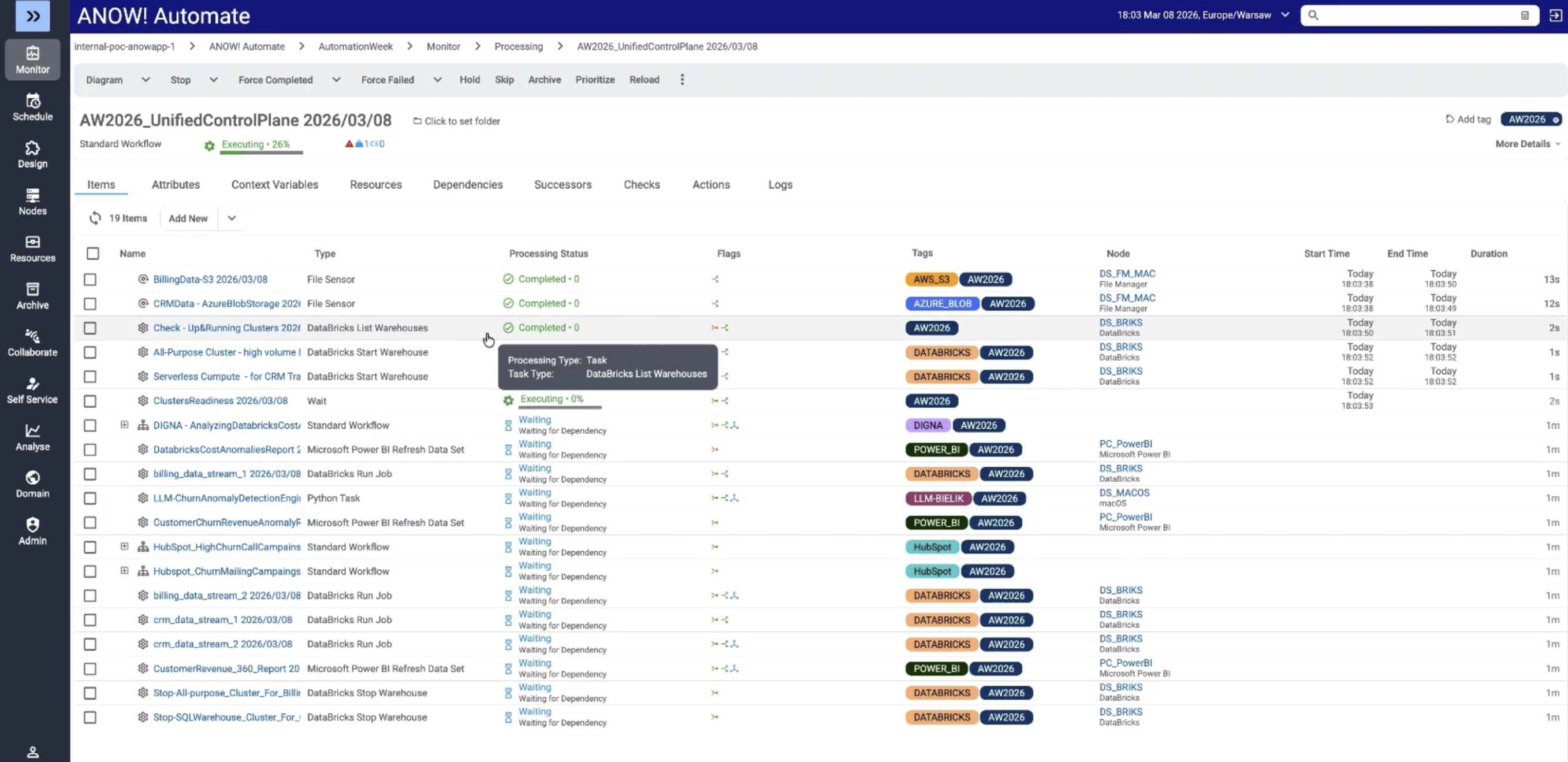
ANOW! Automate ist eine cloud-native Plattform für Workload-Automatisierung und Orchestrierung, die speziell für große Unternehmen mit komplexen, plattformübergreifenden Daten-Workflows entwickelt wurde.
Sie vereint Workflow-Automatisierung, Observability und KI-gestützte Analysen in einer einzigen Lösung und ersetzt damit den Einsatz mehrerer Einzellösungen.
Zu den wichtigsten Funktionen im Bereich Workflow-Automatisierung gehören:
Über 600 native Integrationen, darunter Snowflake, BigQuery, Databricks, dbt, AWS Glue, AWS SageMaker, Azure Data Factory und Apache Airflow
Ein OpenTelemetry-basierter Observability-Layer mit Echtzeit-SLA-Monitoring und automatisierter Fehlerbehebung
Eine ereignisgesteuerte Architektur mit dynamischer Workflow-Generierung, die aus wenigen Definitionen hunderttausende individuelle Workflows erzeugen kann
Eine container-native Architektur auf Kubernetes ohne Downtime für nahtlose Skalierung
Transparente Preisgestaltung bei voller Datenhoheit
Reibungslose Migration von Legacy-Plattformen wie BMC Control-M, Broadcom AutoSys oder Redwood
ANOW! Automate in der Praxis erleben
Erfahren Sie, wie Beta Systems Unternehmen dabei unterstützt, bestehende Workload-Automatisierungsplattformen durch eine moderne, cloud-native Lösung zu ersetzen.
Apache Airflow

Geeignet für: Data-Engineering-Teams, die Python-basierte Pipeline-Orchestrierung einsetzen
Apache Airflow ist eines der am weitesten verbreiteten Open-Source-Frameworks für Workflow-Orchestrierung, mit einem großen Ökosystem und einer aktiven Community. Pipelines werden über in Python definierte DAGs (Directed Acyclic Graphs) modelliert, was besonders für Data Engineers naheliegt, die ohnehin mit Python arbeiten.
Airflow spielt seine Stärken vor allem in Teams aus, die flexibel und codebasiert arbeiten möchten und über die nötigen Ressourcen verfügen, die zugrunde liegende Infrastruktur selbst zu betreiben. Mit wachsender Größe der Datenplattform steigt jedoch auch die operative Komplexität deutlich:
Betrieb und Skalierung auf Kubernetes erfordern dedizierte DevOps-Ressourcen
Eingeschränkte integrierte Observability, für produktives Monitoring sind zusätzliche Tools nötig
Kein Enterprise-Support oder Compliance-Garantien für regulierte Branchen
Hier setzen Plattformen wie ANOW! Automate an. Sie erweitern die Stärken von Airflow um eine Enterprise-taugliche Orchestrierung, inklusive nativer Integration und vollständiger Transparenz über die gesamte Datenlandschaft.
Wenn Sie Airflow bereits im großen Maßstab einsetzen und an operative Grenzen stoßen, lohnt sich ein Blick in den Apache-Airflow-Replacement-Guide von Beta Systems.
dbt (data build tool)
Geeignet für: Analytics- und Data-Transformation-Teams mit Fokus auf SQL-basierte Datenmodelle
dbt hat sich als Standard für Daten-Transformation im modernen Analytics-Stack etabliert. Teams können damit SQL-Transformationen als versionierten und testbaren Code definieren und so Rohdaten in Cloud Data Warehouses wie Snowflake oder BigQuery in saubere, analysefertige Modelle überführen. Integrierte Tests und Dokumentation sorgen zusätzlich für Datenqualität und Nachvollziehbarkeit.
dbt arbeitet auf der Transformationsebene. Es übernimmt weder die Datenaufnahme, noch das Management von systemübergreifenden Abhängigkeiten, SLA-Überwachung oder die Orchestrierung umfassender Workflows. In einer ausgereiften Datenplattform ist dbt daher Teil einer Orchestrierungsschicht und nicht deren Ersatz.
ANOW! Automate integriert sich nativ in dbt. Unternehmen können dbt für SQL-basierte Transformationen nutzen, während ANOW! die vorgelagerten Prozesse wie Datenaufnahme, Abhängigkeitsmanagement, SLA-Steuerung und die durchgängige Observability übernimmt. Beide Lösungen ergänzen sich, statt miteinander zu konkurrieren.
Pro-Tipp
Wenn Ihr Team bereits mit dbt arbeitet, sollten Sie die Orchestrierungsebene separat betrachten. dbt definiert, was mit den Daten passiert. Eine Enterprise-Orchestrierungsplattform steuert, wann etwas passiert, in welcher Reihenfolge und wie bei Fehlern reagiert wird.
So implementieren Sie die Automatisierung von Daten-Workflows
Erfolgreiche Implementierungen starten klein und werden gezielt ausgebaut.
Viele Unternehmen scheitern daran, dass sie versuchen, alle Prozesse gleichzeitig zu automatisieren.
Gehen Sie stattdessen schrittweise vor:
Schritt 1: Bestehende Datenprozesse analysieren und dokumentieren
Bevor Sie ein Tool auswählen, sollten Sie Ihre aktuellen Daten-Workflows vollständig erfassen. Listen Sie alle manuellen Aufgaben auf, schätzen Sie den Zeitaufwand, identifizieren Sie typische Fehlerquellen und markieren Sie compliance-relevante Prozesse.
Priorisieren Sie nach Business Impact: Welche Pipeline-Ausfälle führen zu SLA-Verstößen, Umsatzrisiken oder regulatorischen Problemen? Genau dort sollten Sie ansetzen.
Dokumentieren Sie Datenquellen, Zielsysteme und Transformationslogik
Identifizieren Sie manuelle Eingriffe und deren Häufigkeit
Markieren Sie Workflows mit SLA-Anforderungen oder Audit-Pflichten
Schritt 2: Die passende Automatisierungsarchitektur auswählen
Wählen Sie Tools gezielt für die jeweiligen Ebenen aus.
Ein häufiger Fehler ist es, ein einzelnes Tool auszuwählen und zu erwarten, dass es gleichzeitig Orchestrierung, Observability und umfassendes Workflow-Management übernimmt.
Für die meisten größeren Unternehmen besteht eine sinnvolle Architektur aus drei Ebenen:
Transformationsebene: z. B. dbt für SQL-basierte Analytics-Workflows
Pipeline-Ebene: native Integrationen mit Cloud-Services wie Azure Data Factory, AWS Glue oder BigQuery
Orchestrierungsebene: eine zentrale Workload-Automatisierungsplattform, die alle Ebenen verbindet, SLAs durchsetzt und vollständige Transparenz schafft
→ Weiterlesen: Wie Sie Ihre Automatisierungsstrategie zukunftssicher aufstellen
Schritt 3: Pilotieren, messen und skalieren
Starten Sie mit einem Anwendungsfall, der einen klaren Mehrwert bietet, aber überschaubar bleibt, zum Beispiel:
tägliche Datenaufnahme
eine Reporting-Pipeline
ein wiederkehrender Batch-Job
Setzen Sie den Workflow um, definieren Sie klare Erfolgskriterien (z. B. Laufzeit, Fehlerrate, SLA-Einhaltung) und lassen Sie ihn vier bis sechs Wochen laufen.
Auf Basis dieser Ergebnisse können Sie den internen Business Case für eine breitere Einführung aufbauen. Viele Teams erreichen innerhalb von drei bis sechs Monaten nach einem erfolgreichen Pilotprojekt eine skalierte Umsetzung.
Best Practices für die Automatisierung von Daten-Workflows
Diese Best Practices unterscheiden Teams, die nachhaltig von Automatisierung profitieren, von denen, die dauerhaft mit ihren eigenen Pipelines kämpfen.
Observability
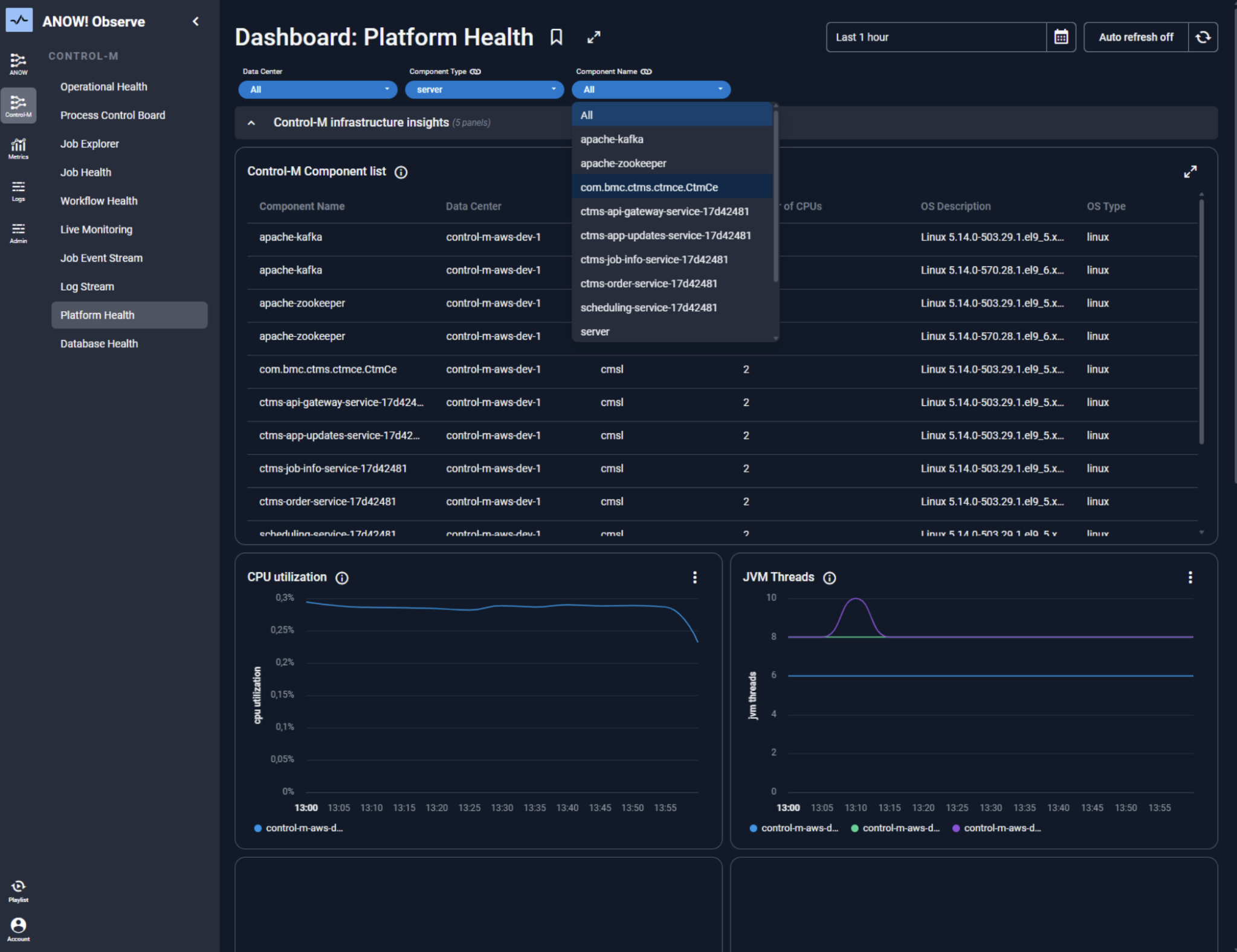
Observability ist kein nachträglich angebautes Monitoring-Dashboard, sondern die Grundlage dafür, dass Automatisierung im großen Maßstab zuverlässig funktioniert.
Jede Pipeline sollte in Echtzeit Einblick geben in Ausführungsstatus, SLA-Einhaltung, Datenqualitätsmetriken und Fehlerkontexte.
Wenn Observability fest in die Orchestrierungsplattform integriert ist, wie etwa bei ANOW! Observe, lassen sich Anomalien frühzeitig erkennen, automatisierte Gegenmaßnahmen auslösen und vollständige Audit-Trails ohne manuellen Aufwand sicherstellen.
Möchten Sie Ihre Daten-Workflows um Echtzeit-Observability erweitern?
ANOW! Observe bietet speziell entwickelte Observability für Workload-Automatisierungsumgebungen, inklusive SLA-Dashboards, Anomalieerkennung und automatisierten Alerts über alle Datenpipelines hinweg.
Fehlerbenachrichtigungen
Jeder automatisierte Daten-Workflow wird früher oder später scheitern. Entscheidend ist nicht, ob ein Fehler auftritt, sondern wie damit umgegangen wird.
Deshalb sollten Retry-Logik, Fehlerbenachrichtigungen und Fallback-Mechanismen von Anfang an Teil jedes Workflows sein. Ebenso wichtig sind klar definierte Eskalationswege, etwa über ein ITSM-Ticket in ServiceNow, eine Slack-Benachrichtigung oder ein automatisiertes Rollback.
Enterprise-Plattformen unterstützen diese Szenarien standardmäßig, ohne dass aufwendige individuelle Skripte notwendig sind.
Automatisierung wie Code behandeln
Workflows, die als Code definiert sind und beispielsweise in Git versioniert sowie über CI/CD-Pipelines ausgerollt werden, lassen sich deutlich einfacher warten, auditieren und bei Bedarf zurücksetzen als rein GUI-basierte Konfigurationen.
Ein „Jobs-as-Code“-Ansatz, wie ihn ANOW! Automate mit JSON-basierten Artefakten und Integration in GitHub, GitLab oder Azure DevOps unterstützt, bringt bewährte Prinzipien aus der Softwareentwicklung in die Workflow-Automatisierung.
Das ist besonders in regulierten Branchen wichtig, in denen sauberes Change Management und vollständige Nachvollziehbarkeit zwingend erforderlich sind.
Starten Sie jetzt mit der Automatisierung Ihrer Daten-Workflows
Bis 2029 werden voraussichtlich 90 Prozent der Unternehmen, die heute noch klassische Workload-Automatisierung einsetzen, auf Service-Orchestration- und Automation-Plattformen umsteigen, um Datenpipelines über hybride IT- und Business-Umgebungen hinweg zu steuern. Unternehmen, die diesen Schritt früh gehen, werden sich klar von denen abheben, die weiterhin reaktiv auf Probleme in ihren Pipelines reagieren.
Die Automatisierung von Daten-Workflows ist das operative Fundament für moderne, cloud-native und KI-fähige Datenplattformen. Wenn Sie aktuell Ihre Workload-Automatisierung modernisieren möchten, sei es als Ablösung von BMC Control-M, Broadcom AutoSys oder eines gewachsenen Inhouse-Schedulers, wurde ANOW! Automate genau für diesen Übergang entwickelt.
Cloud-native, mit konsequentem Fokus auf Observability und über 500 nativen Integrationen, unter anderem für dbt und Apache Airflow, bildet die Plattform die zentrale Orchestrierungsebene für Ihre Daten-Workflows.
Erkunden Sie die Plattform, fordern Sie eine Demo an oder erfahren Sie, wie Sie ohne Downtime von Ihrer bestehenden Lösung migrieren können.
Bereit, Ihre Daten-Workflows zu modernisieren?
Erfahren Sie, wie Unternehmen veraltete Workload-Automatisierung durch eine moderne, cloud-native Orchestrierungsplattform ersetzen – ohne Downtime, ohne Risiko und ohne Vendor Lock-in.
:quality(50))
:quality(50))
:quality(50))