:quality(50))
 Klassische Observability-Plattformen konzentrieren sich auf Infrastruktur, Anwendungen, Services, Logs, Metriken und Traces. All das sind wertvolle Informationen, aber sie erklären nicht automatisch, warum ein Batch-Job sein SLA verletzt hat, welcher Predecessor einen Workflow verzögert hat, ob eine fehlgeschlagene Aufgabe einen geschäftskritischen Prozess beeinträchtigt hat oder wie Workload-Automation-Daten mit dem gesamten operativen Kontext zusammenhängen.
Klassische Observability-Plattformen konzentrieren sich auf Infrastruktur, Anwendungen, Services, Logs, Metriken und Traces. All das sind wertvolle Informationen, aber sie erklären nicht automatisch, warum ein Batch-Job sein SLA verletzt hat, welcher Predecessor einen Workflow verzögert hat, ob eine fehlgeschlagene Aufgabe einen geschäftskritischen Prozess beeinträchtigt hat oder wie Workload-Automation-Daten mit dem gesamten operativen Kontext zusammenhängen.
Genau diese Lücke ist der Grund, warum sich Automation Observability als eigenständige Kategorie etabliert. Im Folgenden finden Sie einen praxisnahen Überblick über 6 Observability-Plattformen, die 2026 in Betracht gezogen werden sollten – mit besonderem Fokus auf den Workload-Automation-Use-Case. ANOW! Observe sticht dabei als einzige Plattform hervor, die von Grund auf speziell für umfassende Automation Observability entwickelt wurde und nicht nur Scheduler-Analytics, Cloud-Monitoring, Dashboarding oder Log-Management abdeckt.
Was ist Automation Observability?
Automation Observability ist die Fähigkeit, Telemetriedaten aus automatisierten Workflows, Jobs, Abhängigkeiten, Infrastruktur, Anwendungen und operativen Ereignissen zu verstehen, zu korrelieren und darauf zu reagieren.
In der Workload Automation lautet die Kernfrage nicht nur: „Ist das System gesund?“, sondern: „Welcher automatisierte Prozess ist betroffen, warum ist er verzögert, welcher Geschäftsservice hängt davon ab und was muss als Nächstes geschehen?“
Das erfordert mehr als technische Dashboards. Es erfordert Automation-Kontext.
Das ist umso wichtiger, weil Automatisierungslandschaften längst nicht mehr einfach sind. Unternehmen betreiben Workloads auf z/OS-Mainframes, verteilten Systemen, Cloud-Plattformen, in Container-Umgebungen, mit RPA-Tools und teils mehreren Workload-Automation-Schedulern. Ohne ein gemeinsames Automation-Modell stehen Teams vor isolierten Monitoring-Inseln, Alarmmüdigkeit, manuellem Aufwand und einer höheren Mean Time to Resolution.
OpenTelemetry entwickelt sich zur tragenden Säule dieses Wandels. In der Studie „Taking Observability to the Next Level: OpenTelemetry’s Emerging Role in IT Performance and Reliability“ von Enterprise Management Associates aus dem Jahr 2025 gaben 92 % der Befragten an, positive Erwartungen an die zukünftige Wirkung von OpenTelemetry auf ihre Observability-Fähigkeiten zu haben – dank verbesserter Interoperabilität, Integration und Skalierbarkeit. Über 46 % der Nutzer sehen bereits einen ROI von mehr als 20 % durch OpenTelemetry, getrieben vor allem durch bessere Observability, Kosteneinsparungen sowie reduzierte Ausfallzeiten und MTTR.
Der nächste Schritt für Observability
Lesen Sie den EMA-Analystenreport und erfahren Sie, wie OpenTelemetry die Zukunft der Observability prägt, operative Effizienz vorantreibt und Innovation in führenden Unternehmen ermöglicht.
Observability-Plattformen im Vergleich: Welche passt am besten zur Workload Automation?
Plattform | Am besten geeignet für | Herausragendes Merkmal | |
|---|---|---|---|
Beta Systems ANOW! Observe | Automation Observability und einheitliche Steuerungsebene | OpenTelemetry-nativer Automation-Kontext für Jobs, Workflows, Logs, Metriken und Abhängigkeiten | |
Broadcom Automation Analytics & Intelligence (AAI) | Automation Analytics für Automatisierungsplattformen aus dem Broadcom-Portfolio | Breite Scheduler-Abdeckung, SLA- und Critical-Path-Analyse | |
Grafana | Technische Observability-Dashboards | Flexible Visualisierung von Metriken, Logs und Traces | |
Datadog | Cloud-native Full-Stack-Observability | Breite Abdeckung von Infrastruktur, Anwendungen, Cloud, Kubernetes, Security und APM | |
BMC Control-M Workflow Insights | Control-M Workflow-Sichtbarkeit | Native Control-M Workflow-Dashboards und Analytics | |
Graylog | Log-Management | Starke zentralisierte Log-Suche, Parsing, Alerting und Analyse |
Beta Systems ANOW! Observe: Die beste Wahl für Automation Observability
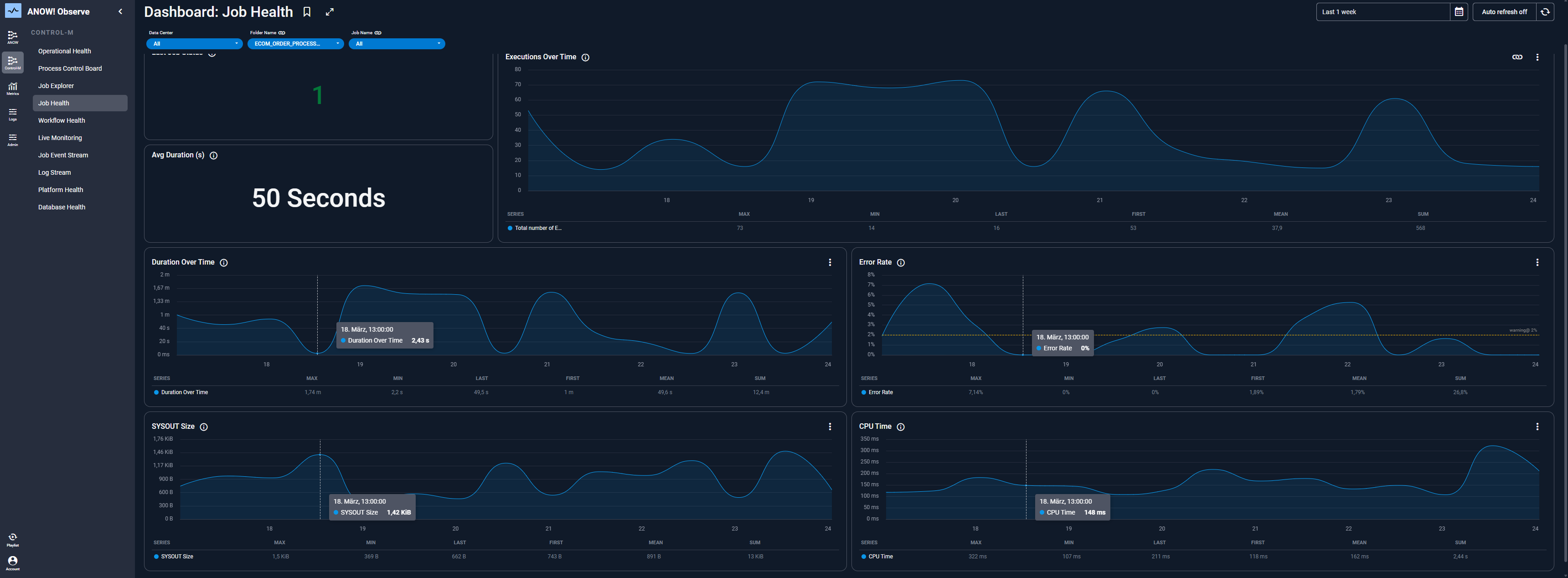
ANOW! Observe ist eine speziell entwickelte Observability-Plattform und Steuerungsebene für den Betrieb von Workload Automation. Sie wurde für BMC Control-M und ANOW! Automate Umgebungen konzipiert und verwandelt Job-Ausführungsdaten in priorisierte Erkenntnisse und automatisierte Gegenmaßnahmen.
Anders als generische Monitoring-Tools ist ANOW! Observe nicht nur eine Dashboard-Schicht über technischen Daten. Die Plattform ist um die Logik der Automatisierung selbst herum aufgebaut: Jobs, Workflows, Task-Abhängigkeiten, Ausführungskontext, SLAs, Agents, Logs und operative Ereignisse.
Damit ist sie besonders relevant für Unternehmen, die geschäftskritische Workloads in heterogenen Umgebungen betreiben: Mainframes, verteilte Systeme, Cloud-Plattformen und zahlreiche Business-Anwendungen. ANOW! Observe schafft eine zentrale Single Pane of Glass für Workloads, indem es OpenTelemetry nutzt, um Telemetriedaten aus unterschiedlichsten Quellen zu sammeln, zu normalisieren und zu vereinheitlichen.
Wichtigste Features
Zentrales Joblog und Output Intelligence: Die Plattform zentralisiert Joblogs, Outputs, Job-Läufe, Abhängigkeiten, Workflow-Ausführungszustände und historische Ausführungsdaten.
OpenTelemetry-Fundament: Die Plattform nutzt OpenTelemetry, um die Datenerfassung zu standardisieren und Interoperabilität mit modernen Observability-Ökosystemen zu ermöglichen.
Prozess- und Workflow-Analytics: Teams können Ausführungsdauer, Erfolgs- und Fehlerraten, Volumina, Trends, SLA-Einhaltung, Engpässe, Anomalien und historisches Workflow-Verhalten nachverfolgen.
Zentrales auditsicheres Archiv für WLA: ANOW! Observe aggregiert Logs aus Anwendungen und Infrastruktur in einem zentralen, auf Workload-Automation-Umgebungen zugeschnittenen Repository – mit Suche, Analytics, Aufbewahrungsrichtlinien sowie sicherer, manipulationsgeschützter Archivierung.
Alerting, Benachrichtigung und ITSM-Integration: Die Plattform unterstützt kontextbezogenes Alerting und Multi-Channel-Benachrichtigungen über Microsoft Teams, Slack, E-Mail sowie Integrationen wie Jira, ServiceNow und Zendesk.
Runbooks und automatisierte Behebung: ANOW! Observe unterstützt Closed-Loop-Remediation-Muster, die Jobs neu starten, Workflows auslösen, Tickets erstellen und zuweisen, Aktionen dokumentieren sowie Runbooks oder Webhooks ausführen können.
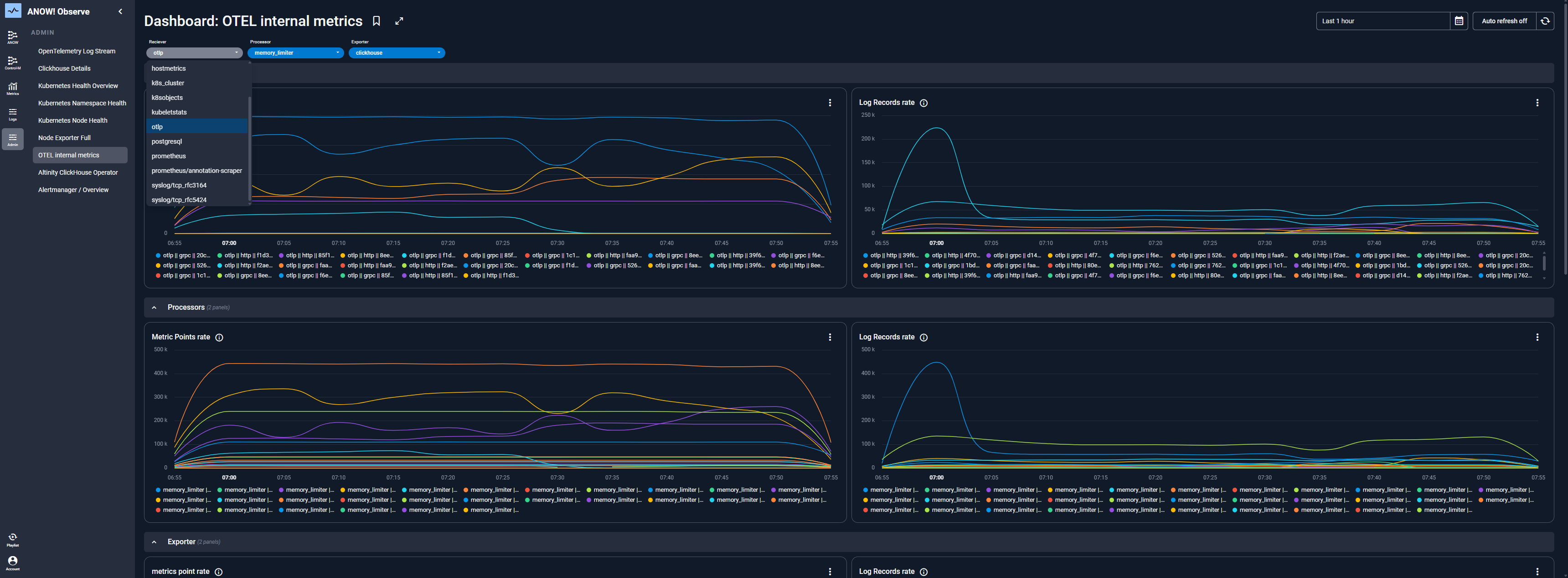
Wo ANOW! Observe überzeugt
Von Grund auf für Automation Observability entwickelt. Viele Tools können Logs, Metriken und Traces sammeln. ANOW! Observe geht weiter, indem es Automation-Telemetrie durch Workload-Automation-Konzepte wie Jobs, Workflows, Abhängigkeiten und Ausführungszustände interpretiert.
Aus Alarmen werden Aktionen. ANOW! Observe basiert auf der Idee, dass Observability nicht bei der Erkennung enden sollte. Mit Alarmkorrelation, Alert-Noise-Reduktion, Benachrichtigungen und gesteuerten Remediation-Workflows verkürzt die Plattform den Weg vom Signal zur Lösung.
Steuerungsebene für die Automatisierung. ANOW! Observe zentralisiert die Sichtbarkeit über Automatisierungssysteme hinweg, verknüpft Ereignisse mit Entscheidungen und Aktionen und ermöglicht die Orchestrierung operativer Antworten. So wird Observability vom passiven Monitoring zur aktiven Operations-Steuerung.
Wo ANOW! Observe weniger passt
Teams, die ausschließlich generische Infrastruktur-Dashboards suchen, sind möglicherweise mit einer breiten technischen Observability-Plattform besser bedient, wenn Workload-Automation-Kontext keine Priorität hat.
Organisationen ohne nennenswerte Workload-Automation-Komplexität benötigen den vollen Mehrwert aus automation-bewusster Telemetrie, Workflow-Korrelation und auditsicherer Joblog-Archivierung möglicherweise nicht.
Für wen geeignet
ANOW! Observe ist die beste Wahl für Unternehmen, die Automatisierung nicht nur auf System-, sondern auf Prozessebene verstehen und steuern müssen.
Am stärksten profitieren typischerweise Organisationen, auf die mehrere dieser Punkte zutreffen:
Eine komplexe Enterprise-Automatisierungslandschaft.
Viele Job-Fehler, Eskalationen oder verzögerte Root-Cause-Analysen.
SLA-getriebene Operations, bei denen späte Erkennung Geschäftsrisiken erzeugt.
Hohes Event-Noise und begrenzte Ende-zu-Ende-Transparenz.
Bedarf an manipulationssicherer Archivierung, Nachvollziehbarkeit und Audit-Fähigkeit.
Kritische Branchen, regulierte Operations oder hohe Compliance-Anforderungen.
Für Teams, die ausschließlich Open-Source-Monitoring, Infrastruktur-Monitoring oder APM ohne übergreifenden Workload-Automation-Observability-Bedarf suchen, ist ANOW! Observe wahrscheinlich nicht der richtige Einstiegspunkt.
Was Kunden sagen:
Wir werden ANOW! Observe als zentrales auditsicheres Archiv nutzen, um die regulatorischen Anforderungen von BaFin und DORA zu erfüllen. Die Zahl der Systeme und Plattformen in unserer Landschaft wächst kontinuierlich, und mit ANOW! Observe schaffen wir eine zentrale Plattform, die einen ganzheitlichen Überblick bietet. Das reduziert nicht nur das Wechseln zwischen verschiedenen Oberflächen, sondern ermöglicht die echte Single Pane of Glass.
Marius Jansen, IT-Spezialist Workload Automation & Scheduling, LVM Versicherung
Automation Observability in Aktion
Die Erfolgsgeschichte der LVM zeigt, wie Enterprise-Automatisierung zur Grundlage für mehr Sichtbarkeit und operative Kontrolle wird.
2. Broadcom Automation Analytics & Intelligence: Die beste Wahl für etablierte Multi-Scheduler-WLA-Analytics
Broadcom Automation Analytics & Intelligence, allgemein bekannt als AAI, ist eine ausgereifte Workload-Automation-Analytics-Plattform. Sie ist besonders stark in Organisationen, die Sichtbarkeit über mehrere Scheduler hinweg benötigen und SLA-Risiken, Critical Paths sowie die Performance von Geschäftsprozessen verstehen wollen.
Die Stärke von AAI liegt in der Breite. Die Plattform unterstützt ein weites Spektrum an Workload-Automation-Umgebungen, darunter Automic, AutoSys, CA 7, Control-M und Airflow. Das macht sie zu einer interessanten Option für Unternehmen mit komplexen Scheduler-Landschaften und Bedarf an herstellerübergreifender Sichtbarkeit.
Wichtige Features
Multi-Scheduler-Sichtbarkeit für Workload Automation.
SLA-, Critical-Path-Management und prädiktive Analytics zur frühzeitigen Erkennung von SLA-Risiken.
Sichtbarkeit von Geschäftsprozessen über einzelne Jobs hinaus.
Wo AAI überzeugt
Reife in Workload-Automation-Analytics. AAI hat eine starke Historie in der Analyse von Scheduler-Daten und der Darstellung plattformübergreifender Automation-Insights.
Hilft Teams beim SLA-Risikomanagement. Die Critical-Path- und Predictive-Funktionen sind nützlich, wenn Teams verstehen müssen, welche Verzögerungen sich auf geschäftliche Zusagen auswirken könnten.
Unterstützt breite WLA-Umgebungen. Für Unternehmen, die bereits auf Broadcom-Automatisierungsplattformen standardisiert sind oder gemischte Scheduler-Landschaften betreiben, kann AAI wertvolle operative Sichtbarkeit liefern.
Wo AAI an seine Grenzen stößt
AAI ist primär analyse- und reporting-getrieben und nicht observability-nativ. Die Plattform setzt auf eine klassische datenbank- und konnektorbasierte Architektur, was zusätzlichen operativen Aufwand und eine Abhängigkeit von Qualität und Verfügbarkeit der angebundenen Scheduler-Daten erzeugen kann.
Außerdem ist AAI nicht OpenTelemetry-nativ und bietet weder das generische Modell aus Logs, Metriken, Traces noch den Automation-Kontext, den eine speziell entwickelte Automation-Observability-Plattform liefert.
Für wen geeignet
AAI passt gut zu Unternehmen, die ausgereifte WLA-Analytics über mehrere Scheduler hinweg benötigen, insbesondere aus dem Broadcom-Portfolio – ist aber nicht die richtige Wahl für Teams, die OpenTelemetry-native Automation Observability suchen.
3. Grafana: Die beste Wahl für flexible technische Observability-Dashboards
Grafana ist eine der am weitesten verbreiteten Observability- und Visualisierungsplattformen. Im Grafana-Stack wird es üblicherweise mit Prometheus für Metriken, Loki für Logs und Tempo für Traces kombiniert. Es ist hochflexibel, herstellerneutral, OpenTelemetry-kompatibel und in Cloud-Native- und Kubernetes-Umgebungen weit verbreitet.
Grafana ist besonders stark, wenn technische Teams genau wissen, welche Datenquellen sie visualisieren wollen und wie sie diese Daten modellieren möchten. Es bietet Engineers eine flexible Leinwand für Dashboards, Alerting und operative Analyse.
Wichtige Features
Flexible Dashboards und Visualisierung.
Starke Metrik-Unterstützung über Prometheus, Log-Analyse über Loki und Trace-Analyse über Tempo.
OpenTelemetry-Kompatibilität.
Wo Grafana überzeugt
Hochgradig anpassbar. Teams können viele Datenquellen anbinden und Dashboards passgenau auf ihre operativen Anforderungen zuschneiden.
Stark in technischer Observability. Grafana funktioniert gut für Infrastruktur-Metriken, Anwendungssignale, Kubernetes-Daten, Logs, Traces und Zeitreihenanalysen.
Großes Ökosystem. Der offene und modulare Ansatz macht Grafana attraktiv für Engineering-Teams, die Flexibilität und Kontrolle wünschen.
Wo Grafana an seine Grenzen stößt
Grafana versteht Workload-Automation-Semantik nicht nativ. Es kann automation-bezogene Daten visualisieren, wenn Teams die richtige Telemetrie einspeisen – aber es weiß nicht automatisch, was ein Job, Workflow, eine Abhängigkeit, ein Predecessor, SLA, Agent oder ein Automation-Ausführungsmodell bedeutet.
Das heißt: Korrelation muss häufig manuell aufgebaut werden. Teams müssen Datenmodelle entwerfen, Eingaben normalisieren, Dashboards erstellen und den Automation-Kontext selbst pflegen. In großen Enterprise-Automatisierungsumgebungen kann das zu Komplexität und Fragmentierung führen.
Für wen geeignet
Grafana ist eine gute Wahl für Platform-Engineering-, DevOps- und SRE-Teams, die flexible Observability-Dashboards benötigen und das Know-how mitbringen, ihre eigenen Daten zu modellieren.
Weniger geeignet ist Grafana, wenn der zentrale Bedarf in Out-of-the-Box-Automation-Observability mit bereits eingebautem Job-, Workflow-, Abhängigkeits- und SLA-Kontext liegt.
4. Datadog: Die beste Wahl für Cloud-native Full-Stack-Observability
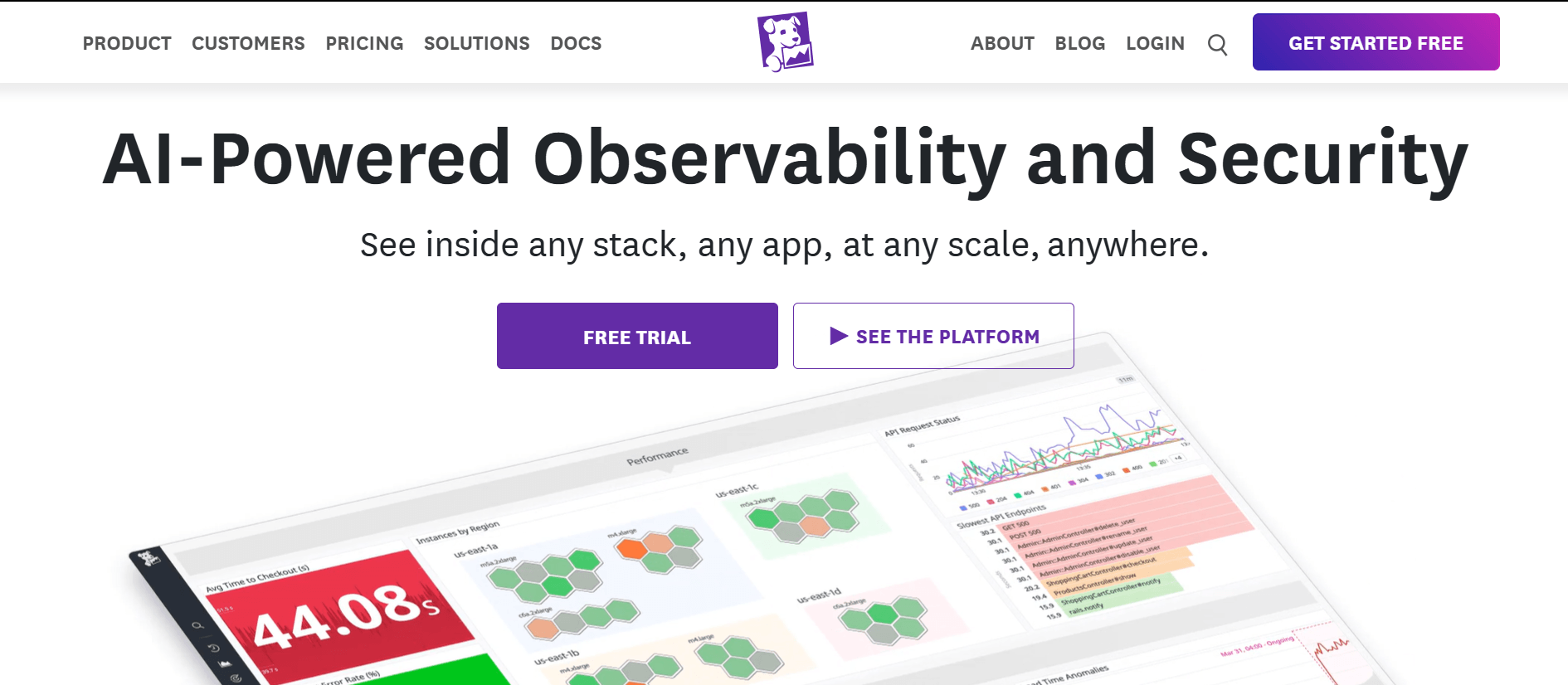
Observability-Plattform, die Infrastruktur- und Cloud-Monitoring, Application Performance Monitoring, Logs, Security, CI/CD-Sichtbarkeit und Kubernetes-Umgebungen abdeckt. Bekannt ist Datadog für schnelle Deployments, agentenbasierte Datenerfassung, umfangreiche Integrationen und Echtzeit-Dashboards.
Wichtige Features
Logs, Metriken, Traces, APM, Infrastruktur-Monitoring, Security, CI/CD und RUM.
Echtzeit-Dashboards und Alerting.
OpenTelemetry-Kompatibilität.
Wo Datadog überzeugt
Breite Abdeckung moderner Umgebungen. Datadog ist stark für Organisationen mit dynamischen Cloud-, Kubernetes-, Microservice- und Anwendungsumgebungen.
Schnelle Implementierung. Agentenbasiertes Deployment und vorgefertigte Integrationen helfen Teams, schnell mit der Erfassung operativer Daten zu starten.
Vereint viele Observability-Use-Cases. Für Infrastruktur-, Application-, Cloud-, Security- und DevOps-Teams bietet Datadog breite Abdeckung in einer Plattform.
Wo Datadog an seine Grenzen stößt
Datadog ist nicht rund um Workload Automation gebaut. Es bietet kein natives semantisches Modell für Batch-Prozesse, Jobs, Workflow-Abhängigkeiten, Scheduler-Ausführungen oder SLA-basierte Automation-Logik.
Die Korrelation basiert auf Telemetriesignalen und nicht auf der Logik von Automatisierungsprozessen. Datadog kann zwar zeigen, dass ein Infrastrukturproblem aufgetreten ist, aber möglicherweise nicht erklären, welcher Automatisierungs-Workflow betroffen war, welcher Predecessor die Verzögerung verursacht hat oder wie sich ein fehlgeschlagener Batch-Prozess auf den geschäftlichen Zeitplan auswirkt.
Für wen geeignet
Datadog ist eine starke Wahl für Cloud-native Engineering-Teams, die breite Full-Stack-Observability für Anwendungen, Infrastruktur, Cloud-Services und Kubernetes benötigen.
Weniger ideal ist es, wenn die Kernanforderung Workload-Automation-Observability mit eingebautem Job-, Workflow-, Abhängigkeits- und SLA-Kontext ist.
Profi-Tipp
Wenn Ihr Team zu viele Alarme bekommt, aber dennoch die entscheidenden Incidents übersieht, liegt das Problem nicht an der Monitoring-Abdeckung. Es fehlt der Automation-Kontext. ANOW! Observe hilft, Job-Events zu korrelieren, Probleme zu priorisieren und Alert-Noise zu reduzieren, bevor Teams Zeit mit manueller Triage verlieren.
5. BMC Control-M Workflow Insights: Die beste Wahl für Sichtbarkeit von Control-M Workflows

BMC Control-M Workflow Insights bietet Einblicke in Control-M Workflows, Job-Verhalten, Trends, Alarme, SLA-Services und Optimierungspotenziale.
Der größte Vorteil liegt in der nativen Control-M-Tiefe. Die Lösung arbeitet mit echten Workflow-Ausführungsdaten und liefert vordefinierte Dashboards für Workflow-Gesundheit, SLA-Performance, Trends, Alarme und kontinuierliche Verbesserung.
Wichtige Features
Tiefe native Integration mit Control-M.
Frühzeitige Erkennung von Performance-Drift und Anomalien.
Nahezu-Echtzeit-Sichtbarkeit des Workflow-Verhaltens.
Skalierbare Such- und Analytics-Grundlage auf Basis von OpenSearch / Elasticsearch.
Wo Control-M Workflow Insights überzeugt
Stark innerhalb von Control-M. Teams, die Control-M intensiv nutzen, profitieren von workflow-spezifischen Insights, ohne Dashboards von Grund auf bauen zu müssen.
Wo Control-M Workflow Insights an seine Grenzen stößt
Die zentrale Einschränkung ist der Scope. Control-M Workflow Insights bietet keinen plattformübergreifenden Ansatz für Automation Observability.
Außerdem ist die Lösung primär analyse- und dashboard-getrieben und nicht observability-nativ. Sie bietet weder ein einheitliches OpenTelemetry-natives Telemetriemodell über Systeme hinweg, noch kombiniert sie Automation-Kontext mit umfassenden Logs, Metriken und Traces für eine tiefere technische Root-Cause-Analyse.
Darüber hinaus kann zusätzliche Infrastruktur wie OpenSearch, Kafka und Zookeeper erforderlich sein, was den Bedarf an CPU, Arbeitsspeicher, Storage und operativem Aufwand erhöhen kann.
Geeignet für
Control-M Workflow Insights eignet sich am besten für Organisationen, die sich klar zu Control-M bekennen und innerhalb dieser Umgebung Workflow-Analytics, SLA-Dashboards und Performance-Einblicke benötigen.
Für Unternehmen, die tool-übergreifende Automation Observability, OpenTelemetry-native Datenerfassung oder ein einheitliches Telemetriemodell über Workload Automation, Infrastruktur, Anwendungen und Hybrid-IT hinweg suchen, ist es nicht geeignet.
6. Graylog: Die beste Wahl für zentralisiertes Log-Management
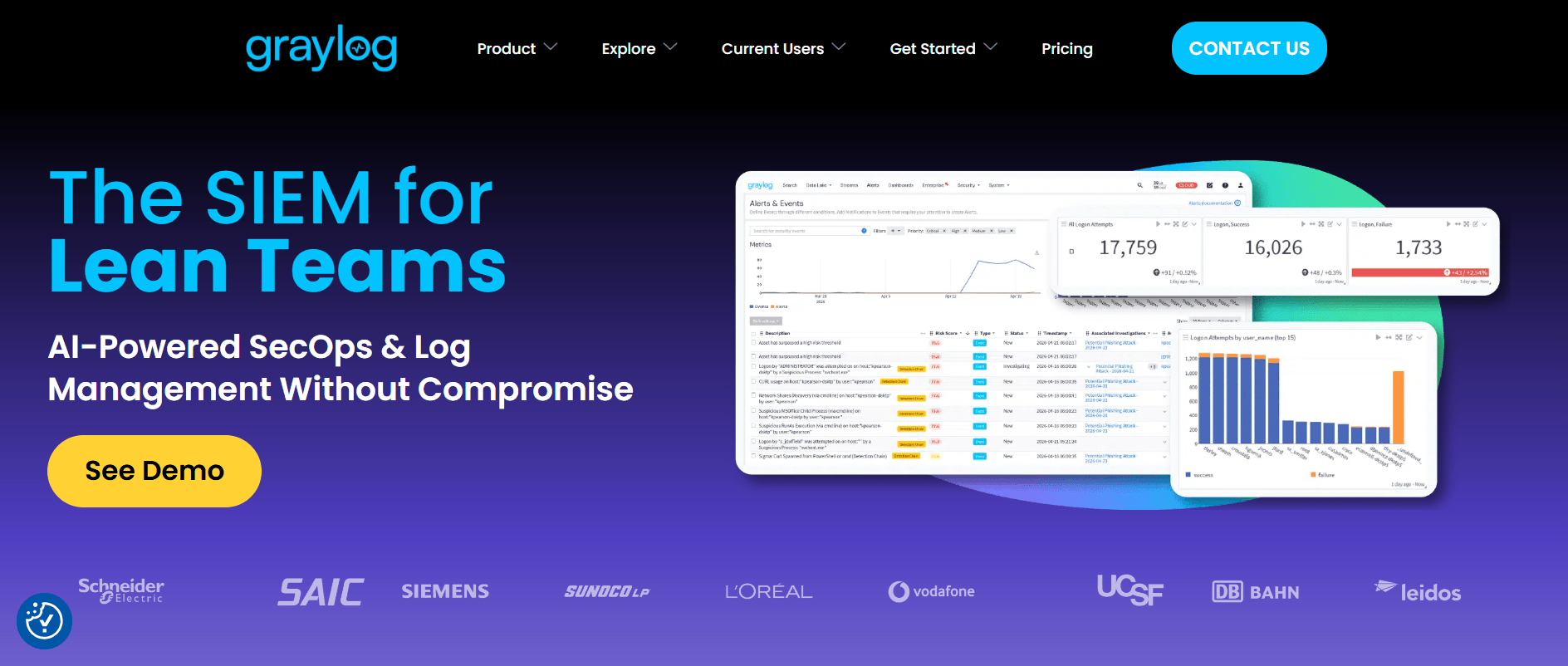
Graylog ist eine logs-first Plattform für zentralisiertes Log-Management, Suche, Parsing, Pipelines, Alerting und Analyse für Security oder IT Operations. Sie lässt sich oft einfacher aufsetzen als große ELK-Umgebungen und ist eine praktische Option für Teams, die Logs aus vielen Quellen sammeln, strukturieren und analysieren möchten.
Wichtige Features
Zentralisierte Log-Erfassung und -Analyse.
Leistungsfähige Suche und Filterung.
Strukturierte Log-Verarbeitung über Parsing und Pipelines.
Alerting- und Event-Funktionen.
Open-Source-Kern mit Enterprise-Erweiterungen.
Integration mit vielen Datenquellen.
Wo Graylog überzeugt
Stark bei Logs. Graylog ist eine praktische Wahl für Teams, die Log-Daten zentralisieren und effizient durchsuchen müssen.
Unterstützt strukturierte Verarbeitung. Pipelines und Parsing helfen Teams, Logs für Analyse und Alerting zu normalisieren.
Wo Graylog an seine Grenzen stößt
Graylog ist keine ganzheitliche Automation-Observability-Plattform. Der Fokus liegt stark auf Logs, mit eingeschränkter oder fehlender nativer Unterstützung für Metriken und Traces im Vergleich zu vollständigen Observability-Plattformen.
Geeignet für
Graylog ist am besten geeignet für Teams, die starkes Log-Management und Event-Analyse benötigen.
Weniger geeignet ist es, wenn das Ziel Ende-zu-Ende-Automation-Observability mit Workload-Automation-Kontext, Abhängigkeits-Mapping, Workflow-Korrelation und OpenTelemetry-nativer Telemetrie ist.
Souverän automatisieren mit ANOW! Observe
Workload Automation ist zu wichtig geworden, um sie mit Tools zu überwachen, die Automatisierung nicht verstehen.
Generische Observability-Plattformen liefern starke Einblicke in Infrastruktur, Anwendungen, Services und Cloud-native Telemetrie. WLA-Analytics-Tools punkten beim Scheduler-Reporting und SLA-Forecasting. Log-Plattformen sind unschlagbar im Erfassen operativer Daten.
Doch Automation Observability braucht mehr: ein Modell, das versteht, wie Automatisierung wirklich funktioniert.
Genau dafür ist ANOW! Observe gebaut. Die Plattform vereint Workload-Automation-Kontext, OpenTelemetry-native Telemetrie, Echtzeit-Prozessüberwachung, Prozessanalytik, Alert-Noise-Reduktion, auditsichere Log-Archivierung und automatisierte Behebung – in einer Lösung für hybride Enterprise-Automatisierung.
ANOW! Observe live erleben
Buchen Sie eine Demo und sehen Sie selbst, wie ANOW! Observe Alert-Noise reduziert, die Workflow-Sichtbarkeit verbessert und operative Reaktionen automatisiert.
:quality(50))
:quality(50))
:quality(50))