:quality(50))
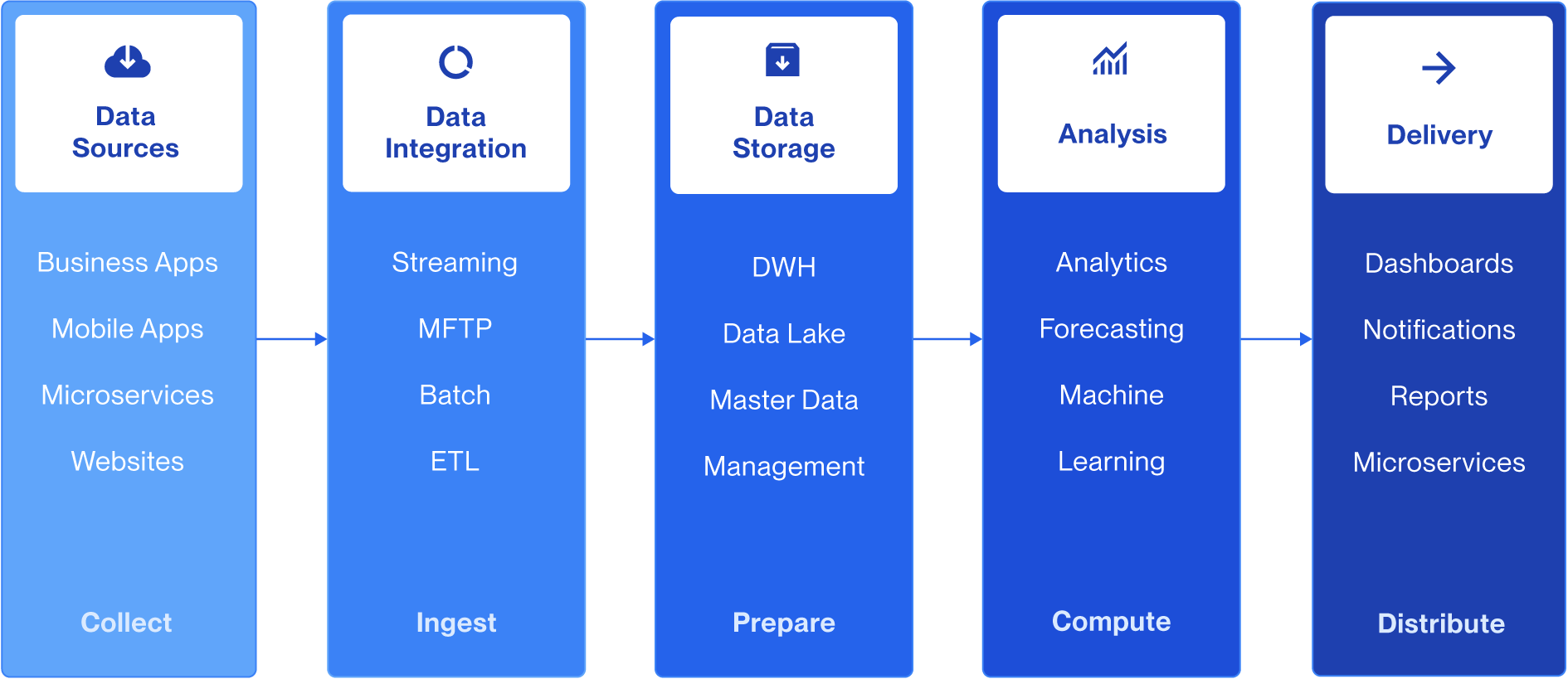
What Is Data Pipeline Orchestration?
Data pipeline orchestration is the automated management of data workflows. This means defining the sequence of tasks (extract, transform, load, validate, deliver), enforcing dependencies between them, handling failures, and monitoring execution across all connected systems.
Think of it as a conductor for your data infrastructure. It doesn't run the instruments itself but it ensures every piece plays at the right moment, in the right order, with the right inputs.
Quick definition:
A data pipeline moves data from source to destination. Orchestration is the layer that decides when, in what order, and under what conditions each step in that pipeline runs.
Unlike simple schedulers that trigger jobs at fixed times, orchestration systems are dependency-aware and event-driven. For example, a downstream task would only run when upstream tasks complete successfully, not simply because a clock says so.
Why Data Pipeline Orchestration Matters
Modern enterprises run dozens, sometimes even hundreds, of interdependent pipelines across cloud platforms, on-premises data centers, SaaS applications, and mainframe systems. Without orchestration, this complexity becomes unmanageable fast.
Eliminates Manual Dependency Management
When Pipeline A feeds Pipeline B, which feeds Pipeline C, a failure at step A can silently corrupt the entire chain.
Orchestration enforces dependency contracts automatically: downstream jobs wait, retry logic kicks in, and alerts fire without human intervention.
Learn more about how workload automation eliminates these manual dependencies.
Delivers End-to-End Visibility
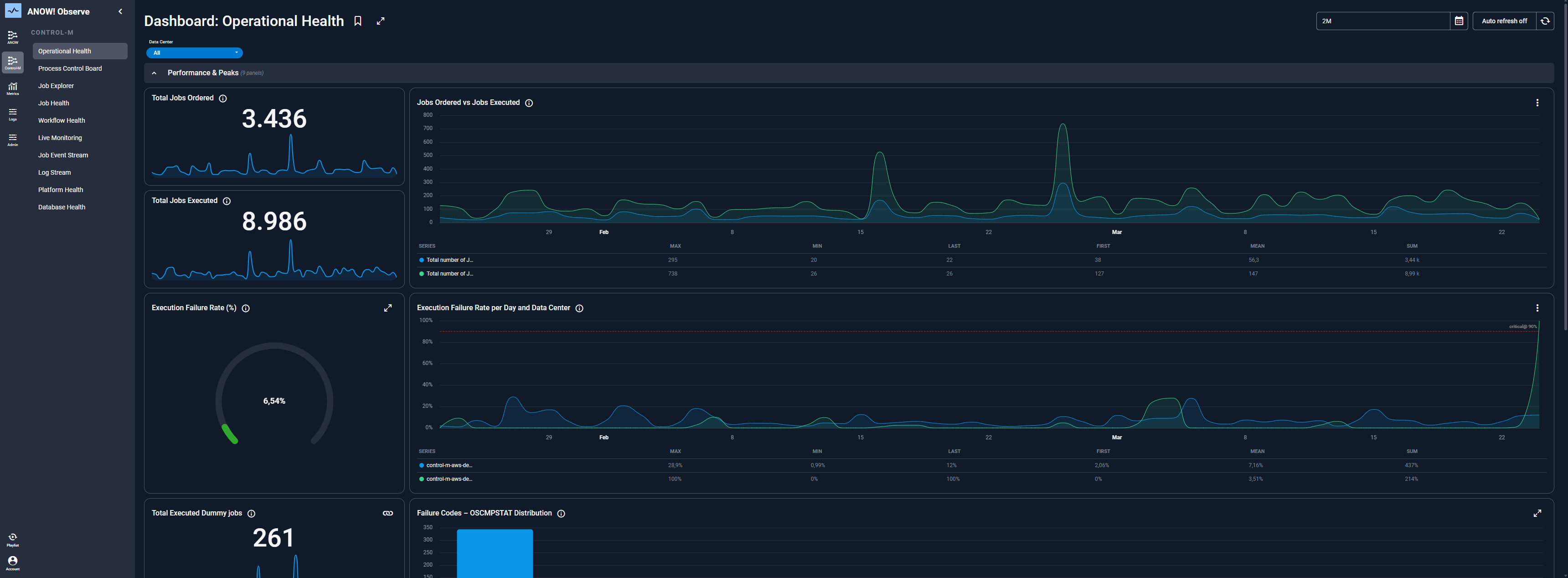
Without centralized orchestration, failures are invisible until something breaks downstream.
Enterprise orchestration platforms provide a single pane of glass across all pipeline activity such as logs, SLA status, execution history, and anomaly alerts, so data teams can act before business users are impacted.
This is where observability for workload automation becomes mission-critical.
Ensures Data Quality and SLA Compliance
Orchestrated pipelines can embed data quality checks as dependencies. If a validation step fails, downstream loads are blocked automatically.
This protects analytical integrity and ensures data SLAs are met consistently.
According to the Gartner Magic Quadrant report, enterprise buyers explicitly expect SOAP platforms to provide “mission-critical reliability” and “centralized control” across their entire hybrid landscape.
See how modern data center automation tools handle cross-system orchestration at enterprise scale.
Scales with Business Complexity
A manually triggered pipeline that works for 10 jobs will collapse at 1,000.
Orchestration platforms scale horizontally, handling thousands of concurrent jobs across multi-cloud and hybrid environments without requiring rearchitecture.
Event-driven automation is a key enabler of this scalability.
Accelerates AI and Analytics Workflows
AI/ML pipelines have strict sequencing requirements:
Data must be cleaned before feature engineering
Features must be validated before model training
Models must be evaluated before deployment
Orchestration enforces these sequences at scale, making data workflow automation at scale a foundation for modern AI operations.
Data Pipeline Orchestration vs Job Scheduling
These terms are frequently confused, but they address fundamentally different problems.
Here are the differences to know.
| Factor | Job Scheduling | Data Pipeline Orchestration |
|---|---|---|
| Primary trigger | Time-based (cron, calendar) | Event-driven + time-based + dependency-based |
| Dependency awareness | None or limited | Full upstream/downstream dependency management |
| Failure handling | Basic retry or alert | Conditional branching, rollback, and escalation logic |
| Cross-system scope | Typically single-platform | Multi-cloud, hybrid, on-prem, SaaS |
| Observability | Job logs only | End-to-end pipeline lineage, SLA dashboards |
| Dynamic execution | Static job definitions | Dynamic workflow generation based on runtime context |
| Use case fit | Routine, time-based batch jobs | Complex, interdependent, multi-system data flows |
Pro Tip
If your pipeline has more than 3 dependent steps or crosses more than one system boundary, you need orchestration.
Common Data Pipeline Architecture Patterns
Data pipelines aren't one-size-fits-all. The right architecture depends on your latency requirements, system landscape, and data volumes.
Here are the four patterns most relevant to enterprise environments.
Batch ETL Pipelines
The most established pattern is that data is extracted from source systems at scheduled intervals (hourly, daily, weekly), transformed according to business rules, and loaded into a target data warehouse or data lake.
Orchestration role
Enforce extraction → transformation → validation → load sequencing
Manage retries for transient failures
Trigger downstream analytics jobs only after successful load confirmation
Common in: Financial reporting, regulatory data submissions, and end-of-day reconciliation in banking and insurance environments
Learn more about how workload automation underpins these workflows.
Streaming and Event-Driven Pipelines
Rather than processing data in bulk at fixed intervals, streaming pipelines process data continuously as events arrive from message queues (Kafka, Kinesis), IoT sensors, application event streams, or API webhooks.
Orchestration role
Manage event-triggered execution, handle backpressure
Coordinate stateful processing
Ensure exactly-once delivery semantics across systems
Common in: Real-time fraud detection, supply chain event monitoring, telecommunications network operations
Hybrid Pipelines (Batch + Streaming)
Many enterprise use cases require both: streaming ingestion for low-latency event capture, combined with batch processing for historical reconciliation and analytics. This Lambda Architecture pattern (or its modern Kappa variant) requires orchestration that can manage both execution models simultaneously.
Orchestration role
Coordinate handoffs between streaming and batch layers
Ensure batch reconciliation jobs consume correct streaming checkpoints
Manage SLAs across both processing modes
Common in: Retail inventory systems, manufacturing quality control, financial risk platforms
Multi-System Pipelines (Cloud + On-Prem)
Enterprise data rarely lives in one place. A single pipeline might extract from an on-premises SAP system, transform via Databricks in the cloud, validate against Snowflake, and load into an Azure Data Warehouse, all as a single orchestrated workflow.
Orchestration role
Abstract infrastructure boundaries
Manage credentials and connectivity across environments
Ensure consistent execution semantics regardless of where each task runs
Common in: SAP modernization projects, cloud migration phases, hybrid BFSI environments where mainframe coexists with cloud-native analytics
Pro Tip
The future of workload automation is increasingly defined by this multi-system, cross-cloud orchestration capability. It's not optional for enterprises managing complex hybrid landscapes.
Core Components of Data Pipeline Orchestration
Understanding what an orchestration platform actually does requires understanding its building blocks.
Scheduler and Trigger Engine
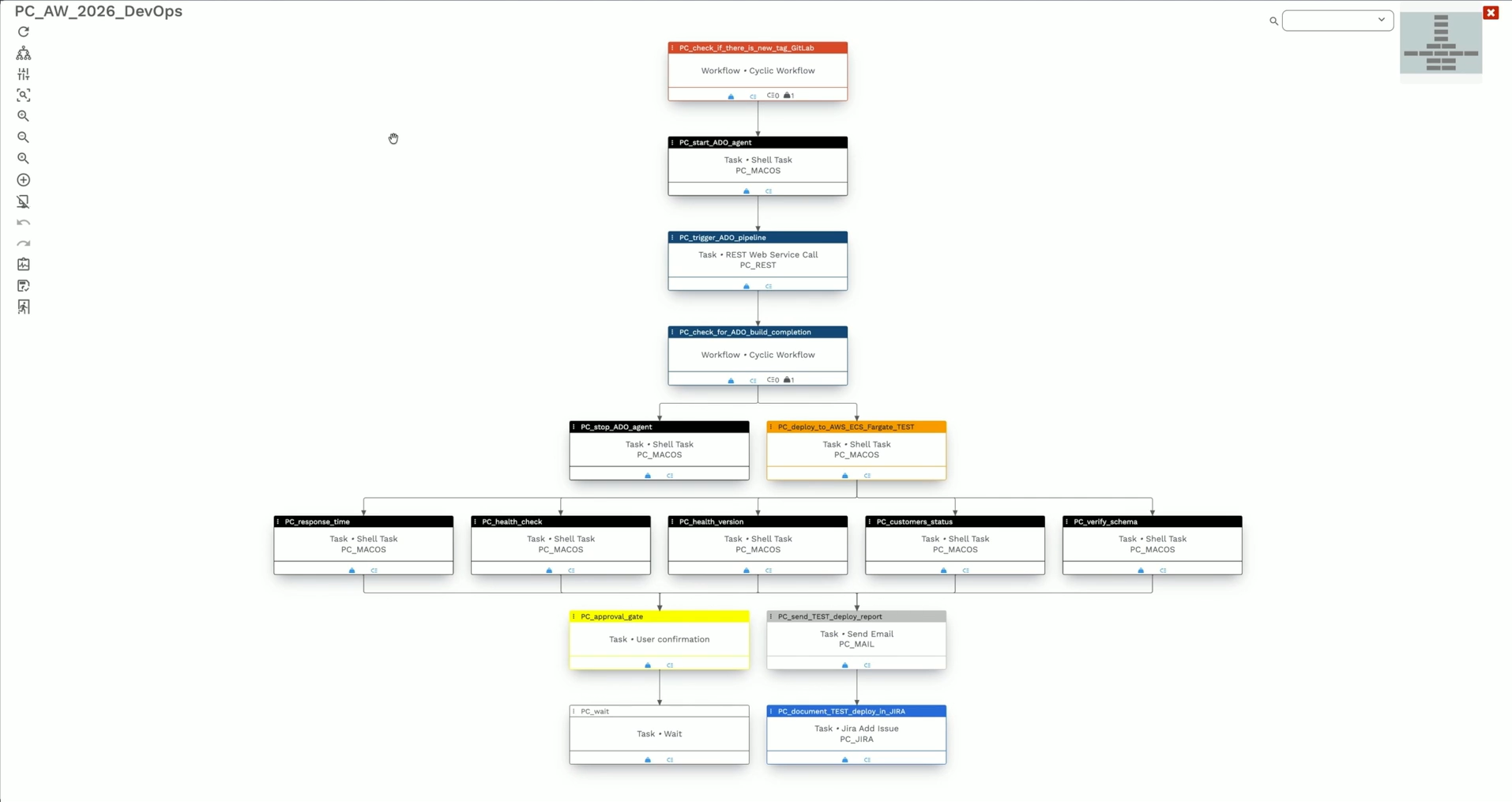
This is the execution backbone, going beyond cron-style time triggers to support event-driven, dependency-based, and API-triggered execution.
Enterprise orchestrators support sensor-based triggers such as a file arriving in an S3 bucket, a database record being updated, or a threshold being crossed in a monitoring system. They are seen as conditions for pipeline execution.
Workflow Designer
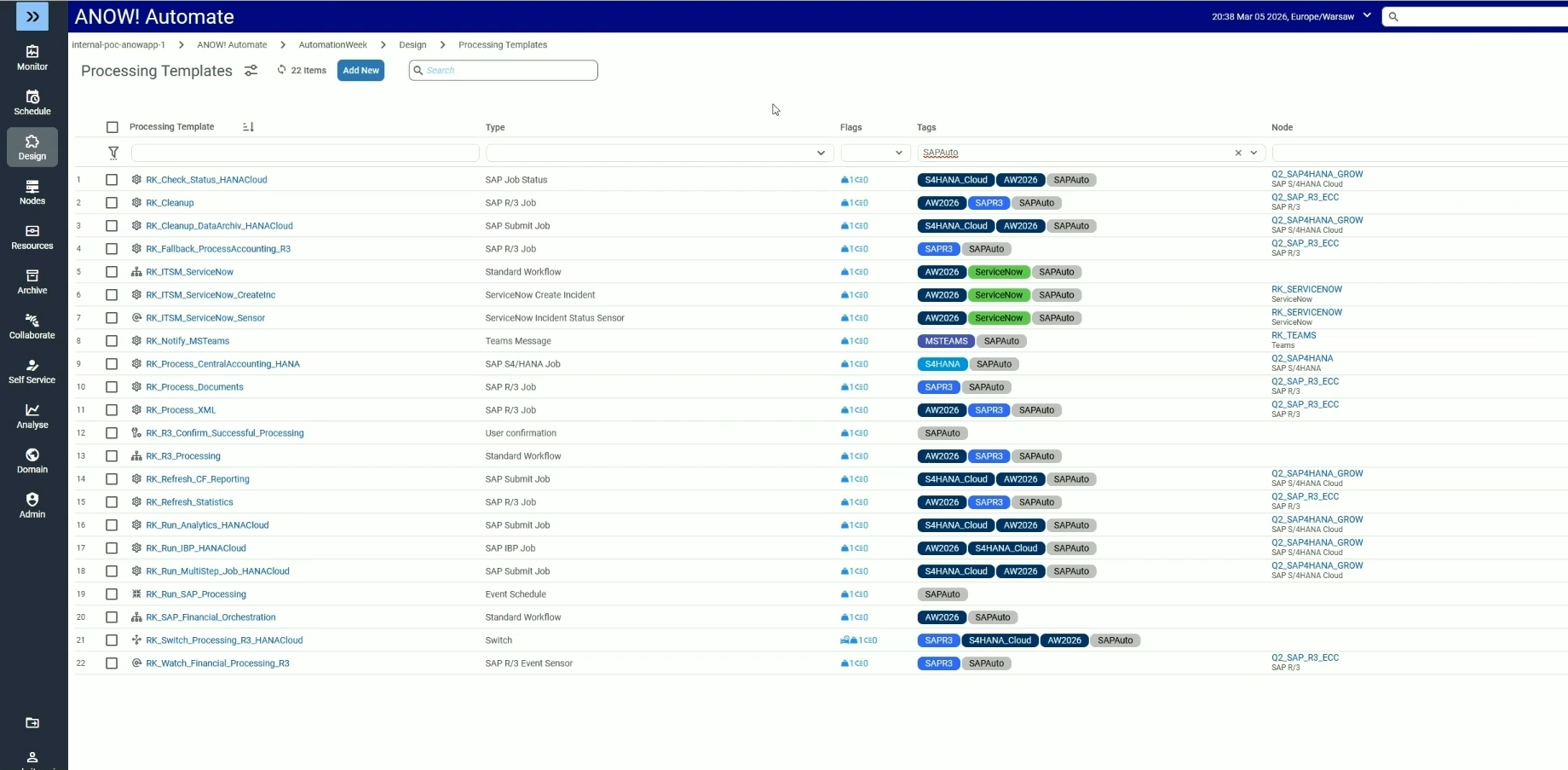
Modern platforms provide both visual (low-code drag-and-drop) and code-based (YAML, JSON, Python) workflow definition options. Enterprise-grade orchestrators support version control and Git integration for CI/CD, critical for DevOps teams managing automation as code.
Error Handling and Recovery Engine
It handles task failures through configurable retry logic, conditional branching (if Step A fails, run Step B instead), rollback capabilities, and escalation paths.
Without robust error handling, a single transient network failure cascades into a full pipeline outage.
Monitoring, Logging, and Observability Layer
It captures execution telemetry and surfaces it through dashboards, alerts, and audit logs. Advanced platforms embed OpenTelemetry support for standardized observability across the entire IT operations management landscape.
This layer is also critical for log management and compliance reporting.
Integration and Connectivity Layer
This measures the breadth of native integrations and determines which systems your orchestration platform can coordinate.
Enterprise environments require connectivity to cloud services (AWS, Azure, GCP), data platforms (Snowflake, Databricks, BigQuery), ERP systems (SAP), ITSM tools (ServiceNow), and legacy infrastructure, all through secure, auditable connections.

Challenges and How to Overcome Them
Even with the right platform, data pipeline orchestration surfaces predictable challenges.
Here's what to expect and how to address each.
#1. Pipeline Sprawl and Lack of Centralized Visibility
As the number of pipelines grows, teams lose track of what’s running, what depends on what, and what’s failing silently. Individual pipeline owners manage their own schedulers, creating invisible dependencies and conflicting resource usage.
The solution? Consolidate all pipeline orchestration under a single platform with unified dashboards and dependency maps. A centralized observability layer, especially one built on OpenTelemetry standards, gives teams real-time visibility across all pipelines simultaneously.
→ Read more: OpenTelemetry's emerging role in IT reliability
#2. Fragile Dependency Management at Scale
Static dependency definitions break when upstream systems change schemas, introduce delays, or fail partially. Hard-coded pipeline logic requires manual intervention for every environmental change.
The solution? Use dynamic workflow generation with sensor-driven triggers rather than static schedules. Platforms like ANOW! Suite support event-driven orchestration adapt automatically to upstream state changes rather than failing on schedule mismatches.
#3. SLA Monitoring Across Hybrid Environments
When pipelines span on-premises and cloud systems, SLA tracking becomes fragmented. Teams discover SLA breaches after the fact, i.e. when business users report missing data, rather than proactively.
The solution? Implement predictive SLA monitoring that flags at-risk pipelines before a breach occurs. Observability for workload automation environments provides the telemetry foundation for proactive SLA management.
#4. Security and Compliance in Data Pipelines
Data pipelines frequently handle sensitive information such as PII, financial records, healthcare data. Ensuring role-based access, audit trails, and compliance with regulations like GDPR and HIPAA across pipeline execution is a persistent challenge.
The solution? Require tag-based, row-level security controls on pipeline components and not just module-level access. Dynamic permission assignment (granting access to a specific pipeline object during execution and revoking it after) ensures the principle of least privilege even in complex orchestration scenarios.
#5. Migration from Legacy Schedulers
Many enterprises are running pipelines on AutoSys, Control-M, or legacy cron-based systems built over decades. Migrating these workloads to modern orchestration platforms without disrupting production is technically and operationally complex.
The solution? Look for platforms with zero-touch migration capabilities and zero-downtime deployment architecture. The ability to run legacy and modern pipelines in parallel during transition reduces risk significantly. Beta Systems' migration approach is specifically designed for enterprises replacing legacy workload automation vendors.
Best Practices for Reliable Data Pipeline Orchestration
Here’s how to best implement data pipeline orchestration for your organization.
#1. Model All Dependencies Explicitly
Never assume upstream data is ready. Instead, encode the dependency in the orchestration layer.
Every pipeline should declare its inputs, outputs, and upstream dependencies so the orchestrator can enforce execution order and surface failures at the point of origin, not downstream.
#2. Implement Idempotent Pipeline Logic
Design pipeline tasks so they can safely re-run after partial failure without duplicating data or corrupting state. This makes retry logic, which is a core orchestration feature, safe to use aggressively, which dramatically reduces downtime from transient failures.
It’s also a core principle behind reliable workflow orchestration.
#3. Adopt Observability as a First-Class Requirement
Treat pipeline telemetry as critical production infrastructure, not an afterthought. Build dashboards for SLA tracking, anomaly detection, and historical trend analysis before you need them.
The ANOW! Observe component is built specifically for this purpose in workload automation environments.
#4. Use Enterprise-Grade Orchestration Platforms, Not Point Tools
Point tools (single-cloud schedulers, purpose-built ETL schedulers) solve narrow problems but create silos.
As Gartner noted in its August 2025 Magic Quadrant, enterprise buyers expect a unified platform to provide centralized control and orchestrate processes end-to-end across their entire hybrid IT landscape.
Platforms like ANOW! Automate offer 600+ native out-of-the-box integrations, more than any other WLA vendor, along with cloud-native deployment, OpenTelemetry-native observability, and zero-downtime upgrade architecture.
#5. Apply Version Control and CI/CD Practices to Pipeline Definitions
Treat workflow definitions as code. Store them in Git, review changes through pull requests, and deploy through CI/CD pipelines.
This prevents undocumented “cowboy” changes to production pipelines and enables rapid rollback when issues occur. Jobs-as-code capabilities are now a standard requirement in modern enterprise orchestration.
Automate Complex Data Workflows With Beta Systems
Data pipeline orchestration is no longer optional for enterprises managing complex, hybrid data environments. It’s become the foundation that makes reliable analytics, AI operations, and business-critical automation possible.
Beta Systems, named a Leader in the 2025 Gartner Magic Quadrant for Service Orchestration and Automation Platforms, is recognized for its unified observability, broad integration capabilities, and high customer retention in mission-critical sectors.
Ready to replace your legacy scheduler or consolidate fragmented pipeline tools?
Explore the ANOW! Suite today.
:quality(50))
:quality(50))
:quality(50))